Bowtie indexerar referensgenomet med hjälp av ett system baserat på Burrows-Wheeler transform (BWT) och FM-indexet . Ett Bowtie-index för det mänskliga genomet passar i 2.2 GB på disken och har ett minnesfotavtryck på så lite som 1.3 GB vid justeringstiden, så att det kan frågas på en arbetsstation med under 2 GB RAM.,
den vanliga metoden för att söka i ett FM-index är Ferragina och Manzinis exakta matchningsalgoritm . Bowtie inte bara anta denna algoritm eftersom exakt matchning inte tillåter sekvenseringsfel eller genetiska variationer. Vi introducerar två nya tillägg som gör tekniken tillämplig på kortläst inriktning: en kvalitetsmedveten backtracking algoritm som tillåter missmatchningar och gynnar högkvalitativa anpassningar; och ”dubbel indexering”, en strategi för att undvika överdriven backtracking., Bowtie aligner följer en policy som liknar Maq: s, eftersom det tillåter ett litet antal missmatchningar inom den högkvalitativa änden av varje läsning, och det placerar en övre gräns för summan av kvalitetsvärdena vid missmatchade justeringspositioner.
Burrows-Wheeler indexering
BWT är en reversibel permutation av tecknen i en text. Även om det ursprungligen utvecklades inom ramen för datakomprimering tillåter BWT-baserad indexering att stora texter söks effektivt i ett litet minnesfotavtryck., Det har tillämpats på bioinformatikapplikationer, inklusive oligomerräkning , helgenomjustering , tiling microarray probe design och Smith-Waterman anpassning till en mänsklig storlek referens .
Burrows-Wheeler-omvandlingen av en text T, BWT(T), är konstruerad enligt följande. Tecknet $ läggs till T, där $ inte är i T och är lexikografiskt mindre än alla tecken i T. Burrows-Wheeler matrisen av T är konstruerad som matrisen vars rader omfattar alla cykliska rotationer av T$. Raderna sorteras sedan lexikografiskt., BWT (T) är sekvensen av tecken i den högra kolumnen i Burrows-Wheeler matrisen (Figur 1a). BWT(T) har samma längd som den ursprungliga texten T.
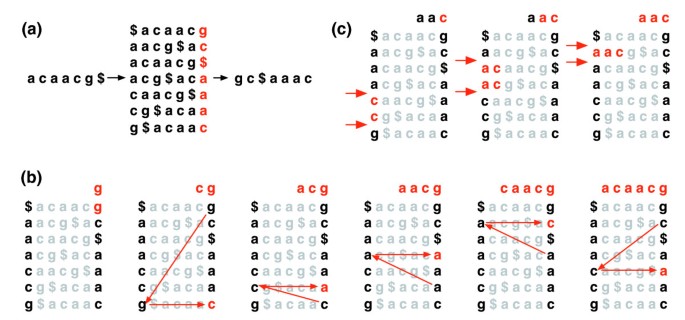
Burrows-Wheeler transform. (a) Burrows-Wheeler matris och omvandling för ”acaacg’. b) åtgärder som vidtas av EXACTMATCH för att identifiera raderna, och därmed uppsättningen referenssuffix, som prefixeras med ”aac”., (c) UNPERMUTE tillämpar upprepade gånger den sista första kartläggningen (LF) För att återställa originaltexten (i rött på topplinjen) från Burrows-Wheeler-transformationen (i svart i kolumnen längst till höger).
denna matris har en egenskap som heter ’last first (LF) mapping’. Ith-förekomsten av tecken X i den sista kolumnen motsvarar samma texttecken som ith-förekomsten av X i den första kolumnen. Den här egenskapen ligger till grund för algoritmer som använder BWT-indexet för att navigera eller söka i texten., Figur 1b illustrerar UNPERMUTE, en algoritm som tillämpar LF-mappningen upprepade gånger för att återskapa T från BWT(T).
LF-mappningen används också i exakt matchning. Eftersom matrisen sorteras lexikografiskt visas rader som börjar med en given sekvens i följd. I en serie steg beräknar EXACTMATCH-algoritmen (figur 1C) intervallet av matrisrader som börjar med successivt längre suffixer av frågan. Vid varje steg krymper storleken på intervallet eller förblir densamma., När algoritmen är klar, rader som börjar med S0 (hela frågan) motsvarar exakta förekomster av frågan i texten. Om intervallet är tomt innehåller texten inte frågan. UNPERMUTE är hänförligt till Hålor och Wheeler och EXACTMATCH att Ferragina och Manzini . Se ytterligare datafil 1 (kompletterande diskussion 1) för mer information.
söka efter inexactjusteringar
EXACTMATCH är otillräckligt för kortläsning eftersom anpassningar kan innehålla felmatchningar, vilket kan bero på sekvenseringsfel, verkliga skillnader mellan referens-och frågeorganismer eller båda., Vi introducerar en justeringsalgoritm som utför en backtracking-sökning för att snabbt hitta anpassningar som uppfyller en angiven anpassningspolicy. Varje tecken i en läsning har ett numeriskt kvalitetsvärde, med lägre värden som indikerar en högre sannolikhet för ett sekvenseringsfel. Vår anpassningspolitik möjliggör ett begränsat antal missmatchningar och föredrar anpassningar där summan av kvalitetsvärdena vid alla missmatchade positioner är låg.
sökningen fortsätter på samma sätt som EXACTMATCH, beräkna matrisintervall för successivt längre frågesuffix., Om intervallet blir tomt (ett suffix förekommer inte i texten) kan algoritmen välja en redan matchad frågeposition och ersätta en annan bas där och införa en obalans i justeringen. EXACTMATCH-sökningen återupptas från strax efter den ersatta positionen. Algoritmen väljer endast de substitutioner som överensstämmer med inriktningspolicyn och som ger ett modifierat suffix som inträffar minst en gång i texten. Om det finns flera kandidat substitutionspositioner, väljer algoritmen girigt en position med ett minimalt kvalitetsvärde.,
backtracking-scenarier spelas upp inom ramen för en stackstruktur som växer när en ny substitution införs och krymper när aligner avvisar alla kandidatjusteringar för de substitutioner som för närvarande finns på stapeln. Se Figur 2 för en illustration av hur sökningen kan fortsätta.
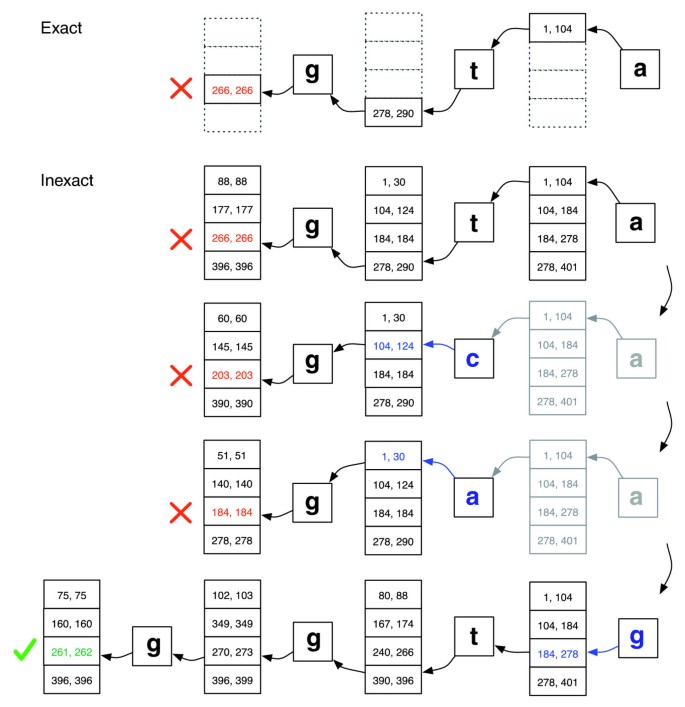
exakt matchning mot inexakt inriktning., Illustration av hur EXACTMATCH (överst) och Fluga är aligner (botten) gå vidare när det inte finns någon exakt matchning för att fråga ’ggta”, men det finns en obalans anpassning när ” a ”ska ersättas med ”g”. Boxade par siffror betecknar intervall av matrisrader som börjar med suffixet observerat fram till den punkten. En röd X markerar där algoritmen möter ett tomt område och antingen avbryter (som i EXACTMATCH) eller backtracks (som i inexact-algoritmen). En grön kontroll markerar där algoritmen finner en nonempty intervall avgränsar en eller flera förekomster av en rapporterbar justering för frågan.,
kort sagt utför Bowtie en kvalitetsmedveten, girig, randomiserad, djupförsta sökning genom utrymmet för möjliga anpassningar. Om en giltig justering finns, då Bowtie kommer att finna det (med förbehåll för backtrack taket diskuteras i följande avsnitt). Eftersom sökningen är girig, kommer den första giltiga anpassningen som Bowtie stöter på inte nödvändigtvis att vara den ”bästa” när det gäller antal felaktigheter eller när det gäller kvalitet., Användaren kan instruera Bowtie att fortsätta söka tills det kan bevisa att någon justering den rapporterar är ”bäst” när det gäller antal missmatchningar (med alternativet-bäst). Enligt vår erfarenhet är det här läget två till tre gånger långsammare än standardläget. Vi förväntar oss att det snabbare standardläget kommer att föredras för stora re-sekvenseringsprojekt.
användaren kan också välja Bowtie att rapportera alla anpassningar upp till ett angivet nummer (option-k) eller alla anpassningar utan gräns för numret (option-A) för en given läsning., Om Bowtie i samband med sin sökning finner n möjliga anpassningar för en viss uppsättning substitutioner, men användaren har begärt endast k anpassningar där K < N, kommer Bowtie att rapportera K av de n inriktningar som valts slumpmässigt. Observera att dessa lägen kan vara mycket långsammare än standard. Enligt vår erfarenhet, till exempel,- K 1 är mer än dubbelt så snabbt som-k 2.
överdriven backtracking
aligner som hittills beskrivits kan i vissa fall stöta på sekvenser som orsakar överdriven backtracking., Detta inträffar när aligner tillbringar det mesta av sin ansträngning fruktlöst backtracking till positioner nära 3 ’ slutet av frågan. Bowtie mildrar överdriven backtracking med den nya tekniken för ”dubbel indexering”. Två index för genomet skapas: en som innehåller BWT av genomet, kallat ”framåt” – indexet, och en sekund som innehåller BWT av genomet med dess teckensekvens omvänd (inte omvänd kompletterad) kallad ”spegel” – indexet. För att se hur detta hjälper, överväga en matchningspolicy som tillåter en obalans i anpassningen., En giltig anpassning med en obalans faller i ett av två fall enligt vilket hälften av läsningen innehåller felmatchningen. Bowtie fortsätter i två faser som motsvarar dessa två fall. Fas 1 laddar framåtindexet i minnet och anropar aligner med begränsningen att det kanske inte ersätter vid positioner i frågans högra hälft. Fas 2 använder spegelindexet och anropar aligner på den omvända frågan, med begränsningen att aligner kanske inte ersätter vid positioner i den omvända frågans högra hälft (den ursprungliga frågan Är vänstra hälften)., Begränsningarna på backtracking i den högra halvan förhindrar överdriven backtracking, medan användningen av två faser och två index upprätthåller full känslighet.
tyvärr är det inte möjligt att undvika överdriven backtracking helt när anpassningar tillåts ha två eller flera felaktigheter. I våra experiment har vi observerat att överdriven backtracking är signifikant endast när en läsning har många lågkvalitativa positioner och inte anpassar eller anpassar sig dåligt till referensen., Dessa fall kan utlösa över 200 backtracks per read eftersom det finns många juridiska kombinationer av lågkvalitativa positioner som ska undersökas innan alla möjligheter är uttömda. Vi mildrar denna kostnad genom att genomdriva en gräns för antalet backtracks tillåtna innan en sökning avslutas (standard: 125). Gränsen förhindrar att vissa legitima, lågkvalitativa anpassningar rapporteras, men vi förväntar oss att detta är en önskvärd avvägning för de flesta applikationer.,
stegvis Maq-liknande sökning
Bowtie tillåter användaren att välja antalet felmatchningar tillåtna (standard: två) i slutet av en läsning av hög kvalitet (standard: de första 28 baserna) samt det maximala acceptabla kvalitetsavståndet för den övergripande inriktningen (standard: 70). Kvalitetsvärden antas följa definitionen i PHRED, där P är sannolikheten för fel och Q = -10log p.
både läsningen och dess omvända komplement är kandidater för anpassning till referensen. För tydlighetens skull anser denna diskussion endast den framåtriktade inriktningen., Se ytterligare datafil 1 (kompletterande diskussion 2) för en förklaring av hur det omvända komplementet införlivas.
de första 28 baserna på den högkvalitativa änden av läsningen kallas ”fröet”. Fröet består av två halvor: 14 bp på den högkvalitativa änden (vanligtvis 5-änden) och 14 bp på den lågkvalitativa änden, kallad ”hi-half ”respektive” lo-half”., Om man antar standardpolicyn (två missmatchningar som tillåts i utsädet) kommer en rapporteringspliktig anpassning att falla i ett av fyra fall: inga missmatchningar i frö (fall 1); Inga missmatchningar i hi-half, en eller två missmatchningar i lo-half (fall 2); inga missmatchningar i Lo-half, en eller två missmatchningar i hi-half (fall 3); och en missmatch i hi-half, en missmatch i lo-half (Fall 4).
alla kundcase tillåter valfritt antal felmatchningar i den icke-obligatoriska delen av läsningen och alla kundcase är också föremål för kvalitetskrav för avstånd.,
Bowtie-algoritmen består av tre faser som växlar mellan att använda fram-och spegelindexen, vilket illustreras i Figur 3. Fas 1 använder spegelindexet och anropar aligner för att hitta anpassningar för fall 1 och 2. Fas 2 och 3 samarbetar för att hitta anpassningar för fall 3: fas 2 finner partiella anpassningar med felaktigheter endast i hi-half och fas 3 försök att förlänga dessa partiella anpassningar till fullständiga anpassningar. Slutligen åberopar fas 3 aligner för att hitta anpassningar för fall 4.,

de tre faserna i Bowtie-algoritmen för den Maq-liknande policyn. En trefas strategi finner anpassningar för två missmatchning fall 1 till 4 samtidigt minimera backtracking. Fas 1 använder spegelindexet och anropar aligner för att hitta anpassningar för fall 1 och 2. Fas 2 och 3 samarbetar för att hitta anpassningar för fall 3: fas 2 finner partiella anpassningar med felaktigheter endast i Hi-half och fas 3 försök att förlänga dessa partiella anpassningar till fullständiga anpassningar., Slutligen åberopar fas 3 aligner för att hitta anpassningar för fall 4.
prestandaresultat
vi utvärderade resultatet av Bowtie med hjälp av läsningar från 1 000 Genomprojektpiloten (National Center for Biotechnology Information Short Read Archive:SRR001115). Totalt 8,84 miljoner läser, om ett körfält av data från ett Illumina-instrument, trimmades till 35 bp och justerades till det mänskliga referensgenomet . Om inget annat anges filtreras eller ändras inte läsdata (förutom trimning) från hur de visas i arkivet., Detta leder till cirka 70% till 75% av läser anpassa någonstans till genomet. Enligt vår erfarenhet är detta typiskt för rådata från arkivet. Mer aggressiv filtrering leder till högre inriktningshastigheter och snabbare anpassning.
alla körningar utfördes på en enda CPU. Bowtie speedups beräknades som ett förhållande mellan väggklockans justeringstider. Både väggklocka och CPU-tider ges för att visa att inmatnings – /utmatningsbelastning och CPU-påstående inte är signifikanta faktorer.
den tid som krävs för att bygga Bowtie-indexet inkluderades inte i Bowtie-körtiderna., Till skillnad från konkurrerande verktyg kan Bowtie återanvända ett förutbestämt index för referensgenomet över många justeringskörningar. Vi räknar med att de flesta användare helt enkelt laddar ner sådana index från ett offentligt förråd. Bowtie-webbplatsen ger index för nuvarande byggnader av människa, chimp, mus, hund, råtta och Arabidopsis thaliana genom, liksom många andra.
resultat erhölls på två hårdvaruplattformar: en stationär arbetsstation med 2,4 GHz Intel Core 2-processor och 2 GB RAM; och en stor minnesserver med en 2,4 GHz AMD Opteron-processor med fyra kärnor och 32 GB RAM., Dessa betecknas ” PC ”respektive ” server”. Både PC och server kör Red Hat Enterprise Linux SOM release 4.
jämförelse med tvål och Maq
Maq är en populär aligner som är bland de snabbaste konkurrerande open source-verktygen för att anpassa miljontals Illumina läser till det mänskliga genomet. Tvål är ett annat open source-verktyg som har rapporterats och använts i kortlästa projekt .
tabell 1 presenterar prestanda och känslighet för Bowtie v0.9.6, tvål v1. 10 och Maq v0. 6. 6. Tvål kunde inte köras på datorn eftersom SOAP minne fotavtryck överstiger datorns fysiska minne. Tvålen.,contig ’ version av SOAP binary användes. För jämförelse med tvål anropades Bowtie med ”- v 2 ”för att efterlikna tvålens standardmatchningspolicy (vilket möjliggör upp till två missmatchningar i anpassningen och ignorerar kvalitetsvärden) och med ”-maxns 5 ” för att simulera tvålens standardpolicy att filtrera ut läser med fem eller flera no-confidence baser. För MAQ-jämförelsen körs Bowtie med sin standardpolicy, som efterliknar Maq: s standardpolicy för att tillåta upp till två missmatchningar i de första 28 baserna och upprätthålla en övergripande gräns på 70 på summan av kvalitetsvärdena vid alla felmatchade läspositioner., För att göra Bowties minnesfotavtryck mer jämförbart med Maq: s, åberopas Bowtie med alternativet ”- z ” i alla experiment för att säkerställa att endast fram-eller spegelindexet är bosatt i minnet på en gång.
antalet avläsningar i linje indikerar att tvål (67,3%) och Bowtie-v 2 (67,4%) har jämförbar känslighet. Av de läsningar som justerades av antingen tvål eller Bowtie, var 99.7% inriktade av båda, 0.2% justerades av Bowtie men inte tvål, och 0.1% justerades av tvål men inte Bowtie. Maq (74,7%) och Bowtie (71,9%) har också ungefär jämförbar känslighet, även om Bowtie släpar med 2,8%., Av de läsningar som justerades av antingen Maq eller Bowtie justerades 96.0% av båda, 0.1% justerades av Bowtie men inte Maq, och 3.9% justerades av Maq men inte Bowtie. Av de läsningar som MAQ mappade men inte Bowtie beror nästan alla på en flexibilitet i MAQS justeringsalgoritm som gör att vissa anpassningar kan ha tre felmatcher i fröet. Resten av läsarna mappade av Maq men inte Bowtie beror på Bowties backtracking tak.
MAQS dokumentation nämner att läsningar som innehåller ”poly-a artefakter” kan försämra MAQS prestanda., Tabell 2 presenterar prestanda och känslighet för Bowtie och Maq när läsuppsättningen filtreras med MAQS ”catfilter” -kommando för att eliminera Poly-a-artefakter. Filtret eliminerar 438,145 av 8,839,010 läser. Andra experimentella parametrar är identiska med experimenten i Tabell 1, och samma observationer om Bowtie och MAQS relativa känslighet gäller här.
Läs längd och prestanda
När sekvenseringstekniken förbättras växer läslängderna bortom 30-bp till 50-bp som vanligtvis ses i offentliga databaser idag., Bowtie, Maq och SOAP support läser av längder upp till 1,024, 63 och 60 bp respektive Maq-versioner 0.7.0 och senare stöder läslängder upp till 127 bp. Tabell 3 visar prestandaresultat när de tre verktygen används för att anpassa tre uppsättningar av 2 M untrimmed läser, en 36-bp-uppsättning, en 50-bp-uppsättning och en 76-bp-uppsättning, till det mänskliga genomet på serverplattformen. Varje set av 2 M är slumpmässigt valda ur ett större set (NCBI Kort Läs Arkiv: SRR003084 för 36-bp, SRR003092 för 50-bp, SRR003196 för 76-bp)., Läsningar samplades så att de tre uppsättningarna av 2 M har enhetlig felfrekvens per bas, beräknat från Per bas Phred kvaliteter. Alla läser passera genom Maq s ’catfilter’.
Bowtie körs både i sitt Maq-liknande standardläge och i sitt tvålliknande ”-v 2 ” – läge. Bowtie ges också alternativet ”- z ” för att säkerställa att endast fram-eller spegelindexet är bosatt i minnet på en gång. Maq v0. 7. 1 användes istället för Maq v0. 6. 6 för 76-bp-uppsättningen eftersom v0. 6.,6 kan inte justera läser längre än 63 bp. Tvål kördes inte på 76-bp-uppsättningen eftersom den inte stöder läser längre än 60 bp.
resultaten visar att MAQ: s algoritm skalar bättre övergripande till längre läslängder än Bowtie eller tvål. Bowtie i tvålliknande ”-v 2 ” – läge skalar emellertid också mycket bra. Bowtie i sin standard MAQ-liknande läge skalor väl från 36-bp till 50-bp läser men är betydligt långsammare för 76-bp läser, även om det fortfarande är mer än en storleksordning snabbare än Maq.,
parallell prestanda
justering kan parallelliseras genom att distribuera läser över samtidiga söktrådar. Bowtie tillåter användaren att ange ett önskat antal trådar (alternativ-p); Bowtie lanserar sedan det angivna antalet trådar med hjälp av pthreads-biblioteket. Bowtie trådar synkroniseras med varandra när Hämta läser, mata ut resultat, växla mellan index, och utföra olika former av global bokföring, såsom märkning en läsning som ”klar”., Annars är trådar fria att fungera parallellt, vilket väsentligt påskyndar inriktningen på datorer med flera processorkärnor. Minnesbilden av indexet delas av alla trådar, så fotavtrycket ökar inte väsentligt när flera trådar används. Tabell 4 visar prestandaresultat för att köra Bowtie v0. 9. 6 på fyrkärniga servern med en, två och fyra trådar.,
Index building
Bowtie använder en flexibel indexeringsalgoritm som kan konfigureras för att växla mellan minnesanvändning och körtid. Tabell 5 illustrerar denna avvägning vid indexering av hela mänskliga referensgenomet (NCBI build 36.3, contigs). Körningar utfördes på serverplattformen. Indexet kördes fyra gånger med olika övre gränser för minnesanvändning.,
de rapporterade tiderna jämför positivt med inriktningstiderna för konkurrerande verktyg som utför indexering under justering. Mindre än 5 timmar krävs för Bowtie att både bygga och fråga helhet-människa-index med 8.84 miljoner läsningar från 1,000 Genome project (NCBI Kort Läs Arkiv:SRR001115) på en server, mer än sex gånger snabbare än motsvarande Maq köra., Den nedersta raden visar att Bowtie indexern, med lämpliga argument, är minneseffektiv nog att köra på en typisk arbetsstation med 2 GB RAM. Ytterligare datafil 1 (kompletterande diskussioner 3 och 4) förklarar algoritmen och innehållet i det resulterande indexet.
programvara
Bowtie är skrivet i C++ och använder seqan-biblioteket . Omvandlaren till MAQ mapping format använder kod från Maq.