Bowtie indexează genomul de referință folosind o schemă bazată pe transformarea Burrows-Wheeler (BWT) și indicele FM . Un indice de Bowtie pentru genomul uman se potrivește în 2.2 GB pe disc și are o amprentă de memorie de până la 1.3 GB la momentul alinierii, permițându-i să fie interogat pe o stație de lucru cu sub 2 GB RAM.,metoda obișnuită de căutare într-un index FM este algoritmul de potrivire exactă a lui Ferragina și Manzini . Bowtie nu adoptă pur și simplu acest algoritm, deoarece potrivirea exactă nu permite erori de secvențiere sau variații genetice. Vom introduce două noi extensii care fac tehnica aplicabile scurt citit aliniere: o calitate conștient algoritm backtracking care vă permite neconcordanțele și favoruri de înaltă calitate aliniamente; și dublu indexarea’, o strategie pentru a evita excesiv backtracking., Bowtie aligner urmează o politică similară cu cea a lui Maq, prin faptul că permite un număr mic de nepotriviri în capătul de înaltă calitate al fiecărei lecturi și plasează o limită superioară a sumei valorilor de calitate la pozițiile de aliniere nepotrivite.
Burrows-Wheeler indexare
BWT este o permutare reversibilă a caracterelor într-un text. Deși inițial dezvoltat în contextul compresiei datelor, indexarea bazată pe BWT permite ca textele mari să fie căutate eficient într-o amprentă de memorie mică., Acesta a fost aplicat aplicațiilor bioinformatice, inclusiv numărarea oligomerilor , alinierea întregului genom , proiectarea sondei microarray și alinierea Smith-Waterman la o referință de dimensiuni umane .
transformarea Burrows-Wheeler a unui text T, BWT (T), este construită după cum urmează. Caracterul $ este adăugat la T, unde $ nu este în T și este lexicografic mai mic decât toate caracterele din T. matricea Burrows-Wheeler a lui T este construită ca matricea ale cărei rânduri cuprind toate rotațiile ciclice ale lui t$. Rândurile sunt apoi sortate lexicografic., BWT (T) este secvența de caractere din coloana din dreapta a matricei Burrows-Wheeler (figura 1a). BWT(T) are aceeași lungime ca și textul original T.
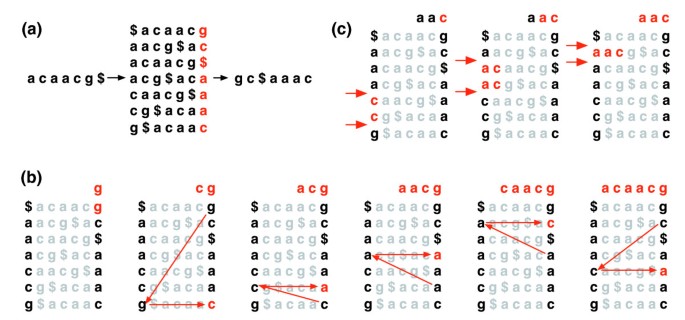
Burrows-Wheeler transforma. (a) matricea vizuini-Wheeler și transformarea pentru „acaacg”. (b) măsurile luate de EXACTMATCH pentru a identifica gama de rânduri și, astfel, setul de sufixe de referință, prefixate de „aac”., (c) UNPERMUTE aplică în mod repetat ultima prima mapare (LF) pentru a recupera textul original (în roșu pe linia de sus) din transformarea Burrows-Wheeler (în negru în coloana din dreapta).
această matrice are o proprietate numită ‘last first (LF) mapping’. A i-a apariție a caracterului X în ultima coloană corespunde aceluiași caracter text ca a i-a apariție a lui X în prima coloană. Această proprietate stă la baza algoritmilor care utilizează indexul BWT pentru a naviga sau a căuta textul., Figura 1B ilustrează UNPERMUTE, un algoritm care aplică maparea LF în mod repetat pentru a re-crea T din BWT(T).
maparea LF este de asemenea utilizată în potrivirea exactă. Deoarece matricea este sortată lexicografic, rândurile care încep cu o secvență dată apar consecutiv. Într-o serie de pași, algoritmul EXACTMATCH (figura 1C) calculează intervalul de rânduri matrice începând cu sufixe succesiv mai lungi ale interogării. La fiecare pas, dimensiunea intervalului se micșorează sau rămâne aceeași., Când algoritmul se finalizează, rândurile care încep cu S0 (întreaga interogare) corespund aparițiilor exacte ale interogării din text. Dacă intervalul este gol, textul nu conține interogarea. UNPERMUTE este atribuită lui Burrows și Wheeler și EXACTMATCH lui Ferragina și Manzini . Consultați fișierul de date suplimentar 1 (discuție suplimentară 1) Pentru detalii.EXACTMATCH este insuficient pentru alinierea scurtă de citire, deoarece aliniamentele pot conține neconcordanțe, care se pot datora erorilor de secvențiere, diferențelor reale între organismele de referință și cele de interogare sau ambele., Introducem un algoritm de aliniere care efectuează o căutare backtracking pentru a găsi rapid aliniamente care îndeplinesc o politică de aliniere specificată. Fiecare caracter dintr-o citire are o valoare numerică de calitate, cu valori mai mici care indică o probabilitate mai mare de eroare de secvențiere. Politica noastră de aliniere permite un număr limitat de neconcordanțe și preferă alinierile în care suma valorilor de calitate la toate pozițiile nepotrivite este scăzută.căutarea se desfășoară în mod similar cu EXACTMATCH, calculând intervalele matricei pentru sufixele de interogare succesive mai lungi., Dacă intervalul devine gol (un sufix nu apare în text), atunci algoritmul poate selecta o poziție de interogare deja potrivită și poate înlocui o bază diferită acolo, introducând o nepotrivire în aliniere. Căutarea EXACTMATCH se reia imediat după poziția substituită. Algoritmul selectează numai acele substituții care sunt în concordanță cu Politica de aliniere și care produc un sufix modificat care apare cel puțin o dată în text. Dacă există mai multe poziții de substituție candidate, atunci algoritmul selectează cu lăcomie o poziție cu o valoare minimă de calitate.,
scenariile de Backtracking se joacă în contextul unei structuri a stivei care crește atunci când este introdusă o nouă substituție și se micșorează atunci când aliniatorul respinge toate aliniamentele candidate pentru substituțiile aflate în prezent pe stivă. Vezi Figura 2 pentru o ilustrare a modului în care s-ar putea desfășura căutarea.
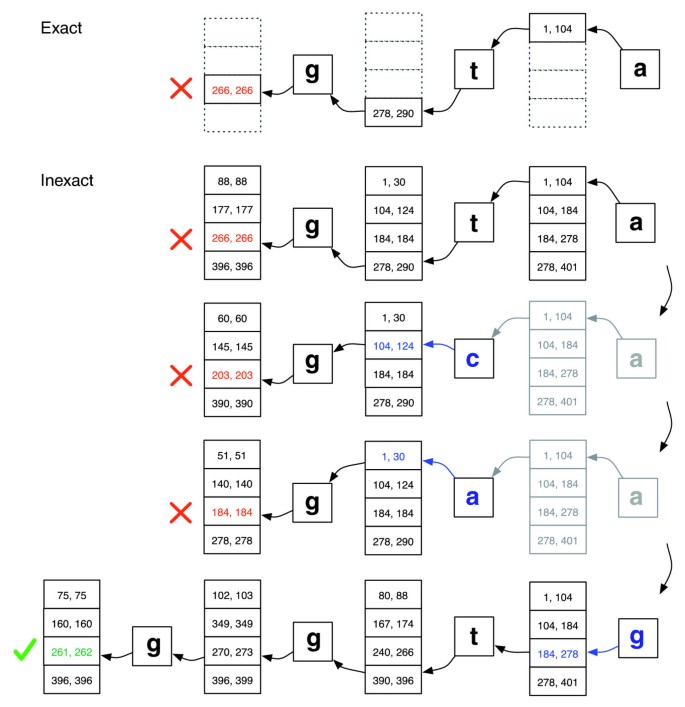
se potrivesc Exact versus inexacte aliniere., Ilustrare a modului EXACTMATCH (de sus) și Aligner Bowtie (de jos) proceda atunci când nu există nici o potrivire exactă pentru interogare „ggta”, dar există o aliniere-o nepotrivire atunci când ” a „este înlocuit cu „g”. Perechile de numere în cutii denotă intervale de rânduri de matrice care încep cu sufixul observat până la acel punct. Un X roșu marchează în cazul în care algoritmul întâlnește un interval gol și fie aborts (ca în EXACTMATCH) sau backtracks (ca în algoritmul inexact). Un marcaj verde în cazul în care algoritmul găsește un interval nonempty delimitând una sau mai multe apariții ale unei alinieri raportabile pentru interogare.,
pe scurt, Bowtie efectuează o căutare conștientă de calitate, lacomă, randomizată, în profunzime prin spațiul posibilelor aliniamente. Dacă există o aliniere validă, atunci Bowtie o va găsi (sub rezerva plafonului backtrack discutat în secțiunea următoare). Deoarece căutarea este lacomă, prima aliniere valabilă întâlnită de Bowtie nu va fi neapărat „cea mai bună” din punct de vedere al numărului de nepotriviri sau din punct de vedere al calității., Utilizatorul poate instrui Bowtie să continue căutarea până când se poate dovedi că orice aliniere raportează este „cel mai bun” în ceea ce privește numărul de neconcordanțe (folosind opțiunea-cel mai bun). În experiența noastră, acest mod este de două până la trei ori mai lent decât modul implicit. Ne așteptăm ca modul implicit mai rapid să fie preferat pentru proiectele mari de re-secvențiere.
utilizatorul poate opta, de asemenea, pentru Bowtie să raporteze toate aliniamentele până la un număr specificat (opțiunea-k) sau toate aliniamentele fără limită a numărului (opțiunea-a) pentru o anumită citire., Dacă în cursul căutării sale Bowtie găsește n posibile aliniamente pentru un anumit set de substituții, dar utilizatorul a solicitat doar aliniamente K unde K < N, Bowtie va raporta K din n aliniamente selectate la întâmplare. Rețineți că aceste moduri pot fi mult mai lente decât cele implicite. În experiența noastră, de exemplu,- k 1 este mai mult de două ori mai rapid decât-k 2.
backtracking excesiv
aligner-ul așa cum este descris până acum poate, în unele cazuri, să întâlnească secvențe care provoacă backtracking excesiv., Acest lucru se întâmplă atunci când aligner își petrece cea mai mare parte a efortului său fără rod backtracking în poziții apropiate de sfârșitul 3′ al interogării. Bowtie atenuează backtracking excesiv cu noua tehnica de „indexare dublă”. Sunt creați doi indici ai genomului: unul care conține BWT-ul genomului, numit indicele „înainte”, și un al doilea care conține BWT-ul genomului, cu secvența de caractere inversată (nu completată invers) numită Indicele „oglindă”. Pentru a vedea cum vă ajută acest lucru, luați în considerare o politică de potrivire care permite o nepotrivire în aliniere., O aliniere validă cu o nepotrivire se încadrează într-unul din cele două cazuri conform cărora jumătate din citire conține nepotrivirea. Bowtie procedează în două faze corespunzătoare celor două cazuri. Faza 1 încarcă indicele înainte în memorie și invocă aligner-ul cu constrângerea pe care nu o poate înlocui la pozițiile din jumătatea dreaptă a interogării. Faza 2 folosește indexul oglindă și invocă aligner-ul pe interogarea inversată, cu constrângerea că aligner-ul nu poate înlocui pozițiile din jumătatea dreaptă a interogării inversate (jumătatea stângă a interogării originale)., Constrângerile privind backtracking-ul în jumătatea dreaptă împiedică backtracking-ul excesiv, în timp ce utilizarea a două faze și doi indici menține sensibilitatea completă.din păcate, nu este posibil să se evite complet backtrackingul excesiv atunci când aliniamentele sunt permise să aibă două sau mai multe neconcordanțe. În experimentele noastre, am observat că backtrackingul excesiv este semnificativ numai atunci când o citire are multe poziții de calitate scăzută și nu se aliniază sau se aliniază prost la referință., Aceste cazuri pot declanșa peste 200 de backtracks pe citire, deoarece există multe combinații legale de poziții de calitate scăzută care trebuie explorate înainte ca toate posibilitățile să fie epuizate. Reducem acest cost prin aplicarea unei limite a numărului de backtracks permise înainte de terminarea unei căutări (implicit: 125). Limita împiedică raportarea unor alinieri legitime, de calitate scăzută, dar ne așteptăm ca acesta să fie un compromis de dorit pentru majoritatea aplicațiilor.,Bowtie permite utilizatorului să selecteze numărul de nepotriviri permise (implicit: două) în capătul de înaltă calitate al unei citire (implicit: primele 28 de baze), precum și distanța maximă de calitate acceptabilă a alinierii generale (implicit: 70). Se presupune că valorile de calitate urmează definiția din PHRED, unde p este probabilitatea de eroare și Q = – 10log p.
atât complementul citit, cât și cel invers sunt candidați pentru alinierea la referință. Pentru claritate, această discuție are în vedere doar orientarea înainte., A se vedea fișierul de date suplimentar 1 (discuție suplimentară 2) pentru o explicație a modului în care complementul invers este încorporat.
primele 28 de baze de pe capătul de înaltă calitate al citirii sunt denumite „semințe”. Sămânța este formată din două jumătăți: 14 bp la capătul de înaltă calitate (de obicei capătul 5′) și 14 bp la capătul de calitate scăzută, denumite „hi-half” și, respectiv, „lo-half”., Presupunând că politica implicită (două nepotriviri permisă în semințe), care face obiectul raportării aliniere va cădea într-una din cele patru cazuri: nu există neconcordanțe în semințe (cazul 1); nu există neconcordanțe în hi-jumătate, una sau două nepotriviri în lo-jumătate (cazul 2); nu există neconcordanțe în lo-jumătate, una sau două nepotriviri în hi-jumătate (cazul 3); și o nepotrivire în hi-jumătate, o nepotrivire în lo-jumătate (cazul 4).
toate cazurile permit orice număr de nepotriviri în partea nonseed a citit și toate cazurile sunt, de asemenea, supuse constrângerii de distanță de calitate.,algoritmul Bowtie constă din trei faze care alternează între utilizarea indicilor forward și mirror, așa cum este ilustrat în Figura 3. Faza 1 utilizează indicele oglindă și invocă aliniamentul pentru a găsi aliniamente pentru cazurile 1 și 2. Fazele 2 și 3 cooperează pentru a găsi alinieri pentru cazul 3: Faza 2 constată alinieri parțiale cu neconcordanțe numai în hi-half și faza 3 încearcă să extindă aceste alinieri parțiale în alinieri complete. În cele din urmă, faza 3 invocă aliniamentul pentru a găsi aliniamente pentru Cazul 4.,

Cele trei faze ale Papion algoritm pentru Maq-cum ar fi politica. O abordare trifazată găsește alinieri pentru cazurile cu două nepotriviri de la 1 la 4, reducând în același timp backtracking-ul. Faza 1 utilizează indicele oglindă și invocă aliniamentul pentru a găsi aliniamente pentru cazurile 1 și 2. Fazele 2 și 3 cooperează pentru a găsi alinieri pentru cazul 3: Faza 2 constată alinieri parțiale cu neconcordanțe numai în hi-half, iar faza 3 încearcă să extindă aceste alinieri parțiale în alinieri complete., În cele din urmă, faza 3 invocă aliniamentul pentru a găsi aliniamente pentru Cazul 4.
rezultate
Am evaluat performanța Papion folosind citește de la 1.000 de Genomuri proiect pilot (National Center for Biotechnology Information Scurt Citi Arhiva:SRR001115). Un total de 8, 84 milioane de citiri, aproximativ o bandă de date de la un instrument Illumina, au fost tăiate la 35 bp și aliniate la genomul uman de referință . Cu excepția cazului în care se specifică altfel, datele citite nu sunt filtrate sau modificate (în afară de tăiere) din modul în care apar în arhivă., Acest lucru duce la aproximativ 70% până la 75% din citirile care se aliniază undeva la genom. Din experiența noastră, acest lucru este tipic pentru datele brute din arhivă. Filtrarea mai agresivă duce la rate mai mari de aliniere și aliniere mai rapidă.
toate rulările au fost efectuate pe un singur procesor. Bowtie speedups au fost calculate ca un raport de ori de aliniere ceas de perete. Ambele perete-ceas și CPU ori sunt date pentru a demonstra că de intrare/ieșire de încărcare și CPU dispută nu sunt factori semnificativi.
timpul necesar pentru a construi indicele Bowtie nu a fost inclus în timpul de funcționare Bowtie., Spre deosebire de instrumentele concurente, Bowtie poate reutiliza un indice pre-calculat pentru genomul de referință în multe runde de aliniere. Anticipăm că majoritatea utilizatorilor vor descărca pur și simplu astfel de indici dintr-un depozit public. Site-ul Bowtie oferă indici pentru construcțiile actuale ale genomului uman, cimpanzeu, șoarece, câine, șobolan și Arabidopsis thaliana, precum și multe altele.rezultatele au fost obținute pe două platforme hardware: o stație de lucru desktop cu procesor Intel Core 2 de 2, 4 GHz și 2 GB RAM; și un server cu memorie mare cu un procesor AMD Opteron de 2, 4 GHz cu patru nuclee și 32 GB RAM., Acestea sunt notate ” PC ” și „server”, respectiv. Atât PC-ul, cât și serverul rulează Red Hat Enterprise Linux ca versiunea 4.
comparație cu SOAP și Maq
Maq este un aligner popular care se numără printre cele mai rapide instrumente open source concurente pentru alinierea a milioane de Lecturi Illumina la genomul uman. SOAP este un alt instrument open source care a fost raportat și utilizat în proiecte cu citire scurtă .Tabelul 1 prezintă performanța și sensibilitatea Bowtie v0.9.6, SOAP v1.10 și Maq v0.6.6. SOAP nu a putut fi rulat pe PC, DEOARECE amprenta de memorie a SOAP depășește memoria fizică a PC-ului. Săpunul.,versiunea contig a binarului de săpun a fost utilizată. Pentru comparație cu SĂPUN, Papionul a fost invocat cu ‘-v 2’ pentru a imita SĂPUN implicit politica de potrivire (care permite până la două nepotriviri în alinierea și ignoră valorile de calitate), și cu ‘–maxns 5’ pentru a simula SĂPUN implicit politica de filtrare a citește cu cinci sau mai multe neîncredere baze. Pentru comparația Maq Bowtie este rulată cu politica implicită, care imită politica implicită a Maq de a permite până la două nepotriviri în primele 28 de baze și de a impune o limită generală de 70 pe suma valorilor de calitate la toate pozițiile de citire nepotrivite., Pentru a face amprenta de memorie a lui Bowtie mai comparabilă cu cea a lui Maq, Bowtie este invocată cu opțiunea „- z ” în toate experimentele pentru a se asigura că numai indicele forward sau mirror este rezident în memorie la un moment dat.numărul de citiri aliniate indică faptul că SOAP (67,3%) și Bowtie-v 2 (67,4%) au o sensibilitate comparabilă. Dintre citirile aliniate fie de săpun, fie de Bowtie, 99.7% au fost aliniate de ambele, 0.2% au fost aliniate de Bowtie, dar nu de săpun, iar 0.1% au fost aliniate de săpun, dar nu de Bowtie. Maq (74.7%) și Bowtie (71.9%) au, de asemenea, o sensibilitate aproximativ comparabilă, deși Bowtie rămâne cu 2.8%., Dintre citirile aliniate fie de Maq, fie de Bowtie, 96.0% au fost aliniate de ambele, 0.1% au fost aliniate de Bowtie, dar nu de Maq, iar 3.9% au fost aliniate de Maq, dar nu de Bowtie. Dintre citirile mapate de Maq, dar nu Bowtie, aproape toate se datorează unei flexibilități în algoritmul de aliniere al Maq, care permite unor aliniamente să aibă trei nepotriviri în sămânță. Restul citirilor mapate de Maq, dar nu Bowtie, se datorează plafonului de backtracking al lui Bowtie.documentația Maq menționează că citirile care conțin „artefacte Poli-A” pot afecta performanța Maq., Tabelul 2 prezintă performanța și sensibilitatea Papion și Maq când citesc set este filtrată folosind Maq e ‘catfilter comandă pentru a elimina poly-O artefacte. Filtrul elimină 438,145 din 8,839,010 citește. Alți parametri experimentali sunt identici cu cei ai experimentelor din tabelul 1 și aceleași observații despre sensibilitatea relativă a Bowtie și Maq se aplică aici.pe măsură ce tehnologia de secvențiere se îmbunătățește, lungimile de citire cresc dincolo de 30-bp la 50-bp frecvent observate în bazele de date publice de astăzi., Suportul Bowtie, Maq și SOAP citește lungimi de până la 1,024, 63 și, respectiv, 60 bp, iar versiunile Maq 0.7.0 și mai târziu suportă lungimi de citire de până la 127 bp. Tabelul 3 prezintă rezultatele performanței atunci când cele trei instrumente sunt utilizate fiecare pentru a alinia trei seturi de citiri de 2 M, un set de 36-bp, un set de 50-bp și un set de 76-bp, la genomul uman de pe platforma serverului. Fiecare set de 2 M este luat la întâmplare dintr-un set mai mare (NCBI Scurt Citi Arhiva: SRR003084 pentru 36-bp, SRR003092 pentru 50-bp, SRR003196 pentru 76-bp)., Citirile au fost prelevate astfel încât cele trei seturi de 2 M să aibă o rată de eroare uniformă pe bază, calculată pe baza calităților Phred per bază. Toate citirile trec prin „catfilterul” lui Maq.
Papion este condusă atât în Maq-ca modul implicit și în SĂPUN-ca ‘-v 2’ modul. Bowtie este, de asemenea, dat opțiunea „- z ” pentru a se asigura că numai indicele înainte sau oglindă este rezident în memorie la un moment dat. Maq v0. 7.1 a fost folosit în loc de Maq v0.6.6 pentru setul 76-bp, deoarece v0.6.,6 nu se poate alinia Citește mai mult de 63 bp. Săpun nu a fost rulat pe setul 76-bp, deoarece nu acceptă Citește mai mult de 60 bp.rezultatele arată că algoritmul lui Maq scalează mai bine în general pentru a citi lungimi mai lungi decât Bowtie sau săpun. Cu toate acestea, Bowtie în modul „-v 2 ” asemănător săpunului se cântărește foarte bine. Bowtie în modul implicit Maq cum ar fi scalează bine de la 36-bp la 50-bp citește, dar este substanțial mai lent pentru 76-bp citește, deși este încă mai mult decât un ordin de mărime mai rapid decât Maq.,
performanță paralelă
alinierea poate fi paralelizată prin distribuirea citirilor între firele de căutare concurente. Bowtie permite utilizatorului să specifice un număr dorit de fire (opțiune-p); Bowtie lansează apoi numărul specificat de fire folosind biblioteca pthreads. Fire Bowtie sincroniza cu fiecare alte atunci când preluarea citește, scoate rezultate, comutarea între indici, și efectuarea diferitelor forme de contabilitate la nivel mondial, cum ar fi marcarea o citire ca „făcut”., În caz contrar, firele sunt libere să funcționeze în paralel, accelerând substanțial alinierea pe computere cu mai multe nuclee de procesor. Imaginea de memorie a indexului este partajată de toate firele, astfel încât amprenta nu crește substanțial atunci când sunt utilizate mai multe fire. Tabelul 4 prezintă rezultatele de performanță pentru rularea Bowtie v0.9. 6 pe serverul cu patru nuclee cu unul, două și patru fire.,
Index clădire
Papion utilizează un sistem flexibil de indexare algoritm care poate fi configurat pentru a comerțului între memorie de utilizare și timpul de funcționare. Tabelul 5 ilustrează acest compromis la indexarea întregului genom uman de referință (NCBI build 36.3, contigs). Rulările au fost efectuate pe platforma serverului. Indexatorul a fost rulat de patru ori cu diferite limite superioare privind utilizarea memoriei.,
a raportat times compara favorabil cu aliniere ori de concurente instrumente care efectua indexarea timpul de aliniere. Mai puțin de 5 ore este necesar pentru Papion la ambele construi și de a interoga un întreg-umane index cu 8.84 milioane de citește de la 1.000 de proiectul Genomului (NCBI Scurt Citi Arhiva:SRR001115) pe un server, mai mult de șase ori mai repede decât echivalentul Maq rula., Cel mai jos rând ilustrează faptul că indexatorul Bowtie, cu argumente adecvate, este suficient de eficient pentru a rula pe o stație de lucru tipică cu 2 GB RAM. Fișier de date suplimentare 1 (discuții suplimentare 3 și 4) explică algoritmul și conținutul indexului rezultat.
Software-ul
Bowtie este scris în C++ și utilizează biblioteca SeqAn . Convertorul în formatul de cartografiere Maq utilizează codul de la Maq.