Bowtie indexeert het referentiegenoom met behulp van een schema gebaseerd op de Burrows-Wheeler transform (BWT) en de FM-index . Een Bowtie-index voor het menselijk genoom past in 2,2 GB op de schijf en heeft een geheugenvoetafdruk van slechts 1,3 GB op het moment van uitlijning, waardoor het kan worden opgevraagd op een werkstation met minder dan 2 GB RAM.,
de gebruikelijke methode voor het zoeken in een FM-index is het exacte-matching algoritme van Ferragina en Manzini . Bowtie neemt dit algoritme niet zomaar over omdat exacte matching geen sequencing van fouten of genetische variaties mogelijk maakt. We introduceren twee nieuwe extensies die de techniek toepasbaar maken op korte leesuitlijning: een kwaliteitsbewust backtracking-algoritme dat mismatches mogelijk maakt en hoogwaardige alignments bevordert; en ‘double indexing’, een strategie om overmatige backtracking te voorkomen., De Bowtie aligner volgt een beleid vergelijkbaar met Maq ‘ s, in die zin dat het een klein aantal mismatches binnen de hoge kwaliteit einde van elke lezing, en het plaatst een bovengrens aan de som van de kwaliteitswaarden op mismatching posities.
Burrows-Wheeler indexing
de BWT is een omkeerbare permutatie van de tekens in een tekst. Hoewel oorspronkelijk ontwikkeld in de context van data compressie, BWT-gebaseerde indexering maakt het mogelijk grote teksten efficiënt te doorzoeken in een kleine geheugen voetafdruk., Het is toegepast op bioinformaticatoepassingen, met inbegrip van oligomeer het tellen , geheel-genoomaanpassing , het betegelen microarray sondeontwerp, en Smith-Waterman aanpassing aan een menselijke-sized verwijzing .
De Burrows-Wheeler transformatie van een tekst T, BWT (T), is als volgt geconstrueerd. Het teken $ is toegevoegd aan T, waar $ niet in T staat en lexicografisch minder is dan alle tekens in T. De Burrows-Wheeler matrix van T is geconstrueerd als de matrix waarvan de rijen alle cyclische rotaties van t$omvatten. De rijen worden dan lexicografisch gesorteerd., BWT (T) is de reeks tekens in de meest rechtse kolom van de Burrows-Wheeler matrix (figuur 1a). BWT (T) heeft dezelfde lengte als de oorspronkelijke tekst T.
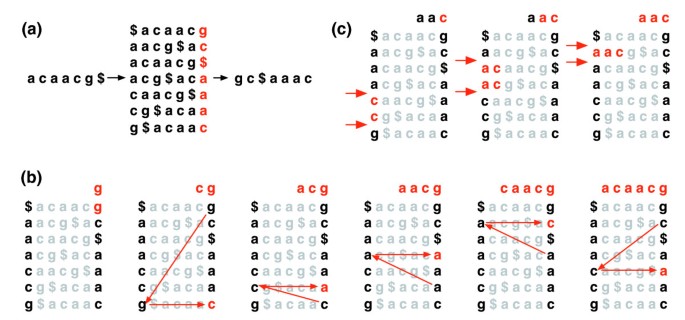
Burrows-Wheeler transform. (A) De Burrows-Wheeler matrix en transformatie voor “acaacg”. b) door EXACTMATCH genomen maatregelen om het rijbereik te identificeren, en dus de reeks referentiesuffixen, voorafgegaan door “aac”., (C) UNPERMUTE past herhaaldelijk de laatste eerste (LF) afbeelding toe om de oorspronkelijke tekst (in rood op de bovenste regel) te herstellen van de Burrows-Wheeler transformatie (in zwart in de meest rechtse kolom).
deze matrix heeft een eigenschap genaamd ‘last first (LF) mapping’. Het IDE voorkomen van teken X in de laatste kolom komt overeen met hetzelfde tekstteken als het IDE voorkomen van X in de eerste kolom. Deze eigenschap ligt ten grondslag aan algoritmen die de BWT-index gebruiken om door de tekst te navigeren of te zoeken., Figuur 1b illustreert UNPERMUTE, een algoritme dat de LF-toewijzing herhaaldelijk toepast om T opnieuw te maken vanuit BWT (T).
de LF-toewijzing wordt ook gebruikt in exacte matching. Omdat de matrix lexicografisch gesorteerd is, verschijnen rijen die met een bepaalde reeks beginnen opeenvolgend. In een reeks stappen berekent het EXACTMATCH-algoritme (figuur 1c) het bereik van matrixrijen die beginnen met achtereenvolgens langere achtervoegsels van de query. Bij elke stap, de grootte van het bereik ofwel krimpt of blijft hetzelfde., Wanneer het algoritme is voltooid, komen rijen die beginnen met S0 (De hele query) overeen met exacte exemplaren van de query in de tekst. Als het bereik leeg is, bevat de tekst de query niet. UNPERMUTE is toe te schrijven aan Burrows en Wheeler en EXACTMATCH aan Ferragina en Manzini . Zie aanvullend gegevensbestand 1 (Aanvullende discussie 1) voor details.
zoeken naar onnauwkeurige uitlijningen
EXACTMATCH is onvoldoende voor korte uitlijning omdat uitlijningen mismatches kunnen bevatten, die het gevolg kunnen zijn van sequentiefouten, echte verschillen tussen referentie-en query-organismen, of beide., We introduceren een uitlijningsalgoritme dat een backtracking-zoekopdracht uitvoert om snel uitlijningen te vinden die voldoen aan een bepaald uitlijningsbeleid. Elk teken in een gelezen heeft een numerieke kwaliteitswaarde, met lagere waarden die een hogere waarschijnlijkheid van een het rangschikken fout aangeven. Ons alignment beleid staat een beperkt aantal mismatches toe en geeft de voorkeur aan alignments waarbij de som van de kwaliteitswaarden op alle mismatches laag is.
De zoekopdracht verloopt op dezelfde manier als EXACTMATCH, waarbij matrixbereiken worden berekend voor achtereenvolgens langere query-achtervoegsels., Als het bereik leeg wordt (een achtervoegsel komt niet voor in de tekst), kan het algoritme een reeds overeenkomende query-positie selecteren en daar een andere basis vervangen, waardoor een mismatch in de uitlijning wordt geïntroduceerd. De EXACTMATCH zoekopdracht wordt hervat van net na de vervangende positie. Het algoritme selecteert alleen die substituties die consistent zijn met het uitlijningsbeleid en die een gewijzigd achtervoegsel opleveren dat ten minste één keer in de tekst voorkomt. Als er meerdere kandidaat-substitutieposities zijn, selecteert het algoritme gretig een positie met een minimale kwaliteitswaarde.,
Backtracking-scenario ‘ s spelen zich af binnen de context van een stackstructuur die groeit wanneer een nieuwe substitutie wordt geïntroduceerd en krimpt wanneer de aligner alle kandidaat-uitlijningen voor de substituties die momenteel op de stack staan afwijst. Zie Figuur 2 voor een illustratie van hoe de zoektocht zou kunnen verlopen.
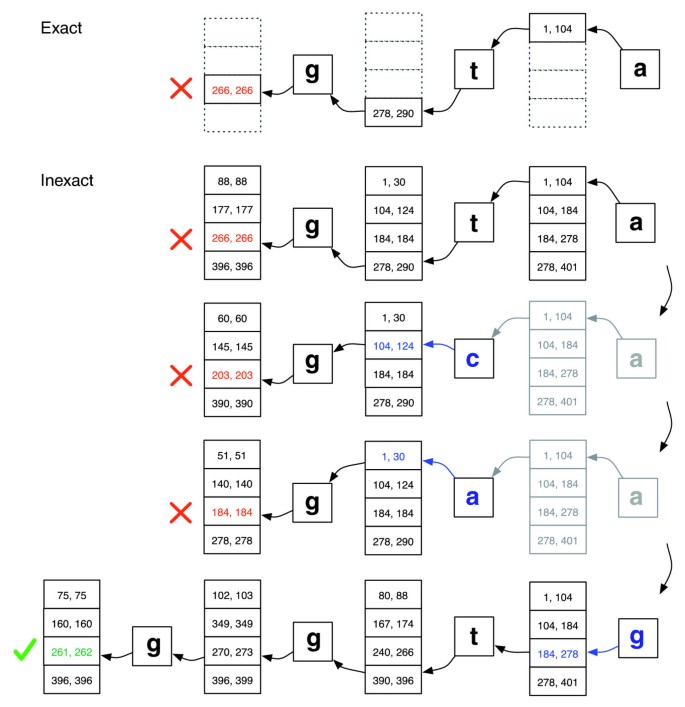
exacte overeenkomst versus onnauwkeurige uitlijning., Illustratie van hoe EXACTMATCH (boven) en Bowtie ’s aligner (onder) verder gaan als er geen exacte overeenkomst is voor query’ ggta’, maar er is een one-mismatch uitlijning wanneer’ a ‘wordt vervangen door’g’. Boxed paren van getallen duiden bereiken van matrixrijen die beginnen met het achtervoegsel waargenomen tot dat punt. Een rode X markeert waar het algoritme een leeg bereik tegenkomt en ofwel afbreekt (zoals in EXACTMATCH) of backtracks (zoals in het onnauwkeurige algoritme). Een groene vinkje markeert waar het algoritme een niet-leeg bereik vindt dat een of meer exemplaren van een te rapporteren uitlijning voor de query begrenst.,
kortom, Bowtie voert een kwaliteitsbewuste, hebzuchtige, gerandomiseerde, diepte-Eerste zoek door de ruimte van mogelijke uitlijningen. Als er een geldige uitlijning bestaat, zal Bowtie deze vinden (onder voorbehoud van het backtrack-plafond dat in de volgende paragraaf wordt besproken). Omdat de zoekopdracht hebzuchtig is, zal de eerste geldige uitlijning die Bowtie tegenkomt niet noodzakelijk de ‘beste’ zijn in termen van aantal mismatches of in termen van kwaliteit., De gebruiker kan Bowtie instrueren door te zoeken totdat hij kan bewijzen dat elke uitlijning die hij rapporteert ‘best’ is in termen van aantal mismatches (met behulp van de optie –best). In onze ervaring is deze modus twee tot drie keer langzamer dan de standaardmodus. We verwachten dat de snellere standaardmodus de voorkeur zal krijgen voor grote re-sequencing projecten.
De gebruiker kan er ook voor kiezen dat Bowtie alle uitlijningen rapporteert tot een bepaald getal (optie-k) of alle uitlijningen zonder limiet op het getal (optie-a) voor een bepaalde lezing., Als Bowtie in de loop van zijn zoekopdracht N mogelijke uitlijningen vindt voor een bepaalde set van vervangingen, maar de gebruiker heeft alleen om K uitlijningen gevraagd waarbij K < N, zal Bowtie K van de willekeurig geselecteerde n uitlijningen rapporteren. Merk op dat deze modi veel langzamer kunnen zijn dan de standaard. In onze ervaring is bijvoorbeeld-k 1 meer dan twee keer zo snel als-k 2.
excessief backtracking
De aligner zoals tot nu toe beschreven kan in sommige gevallen sequenties tegenkomen die excessief backtracking veroorzaken., Dit gebeurt wanneer de aligner besteedt het grootste deel van zijn inspanning vruchteloos backtracking naar posities dicht bij de 3′ einde van de query. Bowtie verzacht overmatige backtracking met de nieuwe techniek van ‘double indexing’. Twee indices van het genoom worden gecreëerd: één met de BWT van het genoom, genoemd de ‘voorwaartse’ index, en een tweede met de BWT van het genoom met zijn karaktervolgorde omgekeerd (niet omgekeerd aangevuld) genoemd de ‘spiegel’ index. Om te zien hoe dit helpt, overweeg een matching beleid dat een mismatch in de uitlijning mogelijk maakt., Een geldige uitlijning met een mismatch valt in een van de twee gevallen volgens welke de helft van de gelezen bevat de mismatch. Bowtie verloopt in twee fasen die overeenkomen met die twee gevallen. Fase 1 laadt de forward index in het geheugen en roept de aligner aan met de beperking die het niet mag vervangen op posities in de rechterhelft van de query. Fase 2 gebruikt de mirror index en roept de aligner aan op de omgekeerde query, met de beperking dat de aligner niet mag vervangen op posities in de omgekeerde query ’s rechter helft (de oorspronkelijke query’ s linker helft)., De beperkingen op het teruglopen naar de rechterhelft voorkomen overmatig teruglopen, terwijl het gebruik van twee fasen en twee indices de volle gevoeligheid behoudt.
helaas is het niet mogelijk om excessieve backtracking volledig te vermijden wanneer alignments twee of meer mismatches mogen hebben. In onze experimenten hebben we opgemerkt dat overmatige backtracking alleen significant is wanneer een read veel posities van lage kwaliteit heeft en niet uitlijnt of slecht afstemt op de referentie., Deze gevallen kunnen leiden tot meer dan 200 backtracks per read omdat er veel juridische combinaties van lage kwaliteit posities worden onderzocht voordat alle mogelijkheden zijn uitgeput. We beperken deze kosten door een limiet op te leggen aan het aantal toegestane backtracks voordat een zoekopdracht wordt beëindigd (standaard: 125). De limiet voorkomt dat sommige legitieme, lage kwaliteit aanpassingen worden gemeld, maar we verwachten dat dit een wenselijke trade-off voor de meeste toepassingen.,
gefaseerde MAQ-achtige zoekopdracht
Bowtie stelt de gebruiker in staat om het aantal toegestane mismatches (standaard: twee) te selecteren in het hoogwaardige einde van een lezen (standaard: de eerste 28 bases) en de maximaal aanvaardbare kwaliteitsafstand van de totale uitlijning (standaard: 70). Kwaliteitswaarden worden verondersteld de definitie in PHRED te volgen, waarbij p de kans op fouten is en Q = -10log p.
zowel de read als de reverse complement zijn kandidaten voor afstemming op de referentie. Voor de duidelijkheid wordt in deze discussie alleen gekeken naar de richting van de toekomst., Zie aanvullend gegevensbestand 1 (Aanvullende bespreking 2) voor een uitleg van hoe het omgekeerde complement is opgenomen.
de eerste 28 bases op het hoogwaardige einde van de read worden de “seed” genoemd. Het zaad bestaat uit twee helften: de 14 bp op het hoogwaardige uiteinde (meestal het 5′-uiteinde) en de 14 bp op het lage kwaliteit uiteinde, respectievelijk de ‘hi-half’ en de ‘lo-half’ genoemd., Uitgaande van de standaard beleid (twee mismatches toegestaan in het zaad), een te rapporteren uitlijning zal vallen in een van de vier gevallen: geen verschillen in zaad (case 1); geen verschillen in de hi-helft, één of twee verschillen in de lo-helft (case 2); geen verschillen in de lo-helft, één of twee verschillen in de hi-helft (zaak 3); en een mismatch in de hi-helft, een mismatch in de lo-helft (geval 4).
alle cases staan een aantal mismatches toe in het niet-verplichte deel van het lezen en alle cases zijn ook onderworpen aan de kwaliteitsafstandsbeperking.,
Het Bowtie-algoritme bestaat uit drie fasen die afwisselen tussen het gebruik van de forward-en mirror-indices, zoals geïllustreerd in Figuur 3. Fase 1 gebruikt de mirror index en roept de aligner aan om alignments te vinden voor gevallen 1 en 2. Fase 2 en 3 werken samen om alignments te vinden voor geval 3: Fase 2 vindt gedeeltelijke alignments met mismatches alleen in de hi-half en fase 3 pogingen om die gedeeltelijke alignments uit te breiden tot volledige alignments. Tot slot roept fase 3 de aligner op om alignments te vinden voor geval 4.,

De drie fasen van het Bowtie-algoritme voor het MAQ-achtige beleid. Een driefasige aanpak vindt alignments voor twee-mismatch gevallen 1 tot 4 terwijl het minimaliseren van backtracking. Fase 1 gebruikt de mirror index en roept de aligner aan om alignments te vinden voor gevallen 1 en 2. Fase 2 en 3 werken samen om alignments te vinden voor geval 3: Fase 2 vindt gedeeltelijke alignments met mismatches alleen in de hi-half, en fase 3 probeert die gedeeltelijke alignments uit te breiden tot volledige alignments., Tot slot roept fase 3 de aligner op om alignments te vinden voor geval 4.
Performance results
We evalueerden de prestaties van Bowtie aan de hand van reads uit de 1000 genomen project pilot (National Center for Biotechnology Information Short Read Archive:SRR001115). Een totaal van 8.84 miljoen reads, ongeveer een Rij gegevens van een Illumina-instrument, werden bijgesneden tot 35 bp en afgestemd op het menselijke referentiegenoom . Tenzij anders aangegeven, worden gelezen gegevens niet gefilterd of gewijzigd (behalve bijsnijden) van hoe ze in het archief verschijnen., Dit leidt tot ongeveer 70% tot 75% Van Leest die zich ergens aan het genoom richten. In onze ervaring is dit typisch voor ruwe data uit het archief. Agressievere filtering leidt tot hogere uitlijningssnelheden en snellere uitlijning.
alle runs werden uitgevoerd op een enkele CPU. Bowtie speedups werden berekend als een verhouding van de wand-klok uitlijning tijden. Zowel wand-klok en CPU tijden worden gegeven om aan te tonen dat input/output belasting en CPU stelling zijn geen significante factoren.
De tijd die nodig is om de Bowtie index te bouwen was niet opgenomen in de Bowtie running times., In tegenstelling tot concurrerende instrumenten, kan Bowtie een vooraf berekende index voor het referentiegenoom hergebruiken over vele uitlijningsronden. We verwachten dat de meeste gebruikers dergelijke indices gewoon zullen downloaden van een publieke repository. De Bowtie site biedt indices voor de huidige builds van de menselijke, chimpansee, muis, hond, rat, en Arabidopsis thaliana genomen, evenals vele anderen.
resultaten werden verkregen op twee hardwareplatforms: een desktopwerkstation met 2,4 GHz Intel Core 2 processor en 2 GB RAM; en een server met groot geheugen met een 4-core 2,4 GHz AMD Opteron processor en 32 GB RAM., Deze worden aangeduid als ‘PC’ en ‘server’, respectievelijk. Zowel PC als server draaien Red Hat Enterprise Linux als release 4.
vergelijking met SOAP en Maq
Maq is een populaire aligner die behoort tot de snelste concurrerende open source tools voor het uitlijnen van miljoenen Illumina reads naar het menselijk genoom. SOAP is een andere open source tool die is gemeld en gebruikt in verkorte projecten.
Tabel 1 geeft de prestaties en gevoeligheid weer van Bowtie v0. 9. 6, SOAP v1. 10 en Maq v0. 6.6. SOAP kon niet worden uitgevoerd op de PC omdat SOAP ‘ s geheugen voetafdruk groter is dan het fysieke geheugen van de PC. De zeep.,contig ‘ versie van de SOAP binary werd gebruikt. Voor vergelijking met SOAP werd Bowtie aangeroepen met ‘-v 2’ om het standaard matchingbeleid van SOAP na te bootsen (dat tot twee mismatches in de uitlijning mogelijk maakt en kwaliteitswaarden negeert), en met ‘–maxns 5’ om het standaardbeleid van SOAP te simuleren om leesuitfilters uit te filteren met vijf of meer vertrouwenspersonen. Voor de MAQ-vergelijking wordt Bowtie uitgevoerd met zijn standaardbeleid, dat MAQ ‘ s standaardbeleid nabootst van het toestaan van maximaal twee mismatches in de eerste 28 bases en het afdwingen van een totale limiet van 70 op de som van de kwaliteitswaarden op alle mismatched leesposities., Om Bowtie ’s memory footprint meer vergelijkbaar te maken met Maq’ s, wordt Bowtie in alle experimenten met de ‘- z ‘ optie aangeroepen om ervoor te zorgen dat alleen de forward of mirror index in het geheugen aanwezig is.
het aantal uitgelijnde reads geeft aan dat SOAP (67,3%) en Bowtie-v 2 (67,4%) een vergelijkbare gevoeligheid hebben. Van de reads uitgelijnd door ofwel SOAP of Bowtie, 99,7% werd uitgelijnd door beide, 0,2% werd uitgelijnd door Bowtie maar niet SOAP, en 0,1% werd uitgelijnd door SOAP maar niet Bowtie. Maq (74,7%) en Bowtie (71,9%) hebben ook ongeveer vergelijkbare gevoeligheid, hoewel Bowtie blijft met 2,8%., Van de reads uitgelijnd door ofwel Maq of Bowtie, 96,0% werd uitgelijnd door beide, 0,1% werd uitgelijnd door Bowtie maar niet Maq, en 3,9% werd uitgelijnd door Maq maar niet Bowtie. Van de reads in kaart gebracht door Maq maar niet Bowtie, zijn bijna allemaal te wijten aan een flexibiliteit in MAQ ‘ s uitlijningsalgoritme dat het mogelijk maakt dat sommige uitlijningen drie mismatches in het zaad hebben. De rest van de reads in kaart gebracht door Maq maar niet Bowtie zijn te wijten aan Bowtie ‘ s backtracking plafond.
Maq ‘ s documentatie vermeldt dat lezen die ‘poly-a artefacten’ bevatten de prestaties van Maq kan aantasten., Tabel 2 toont de prestaties en gevoeligheid van Bowtie en Maq wanneer de leesset wordt gefilterd met behulp van Maq ‘s’ catfilter ‘ commando om poly-a artefacten te elimineren. Het filter elimineert 438.145 van de 8.839.010 reads. Andere experimentele parameters zijn identiek aan die van de experimenten in Tabel 1, en dezelfde waarnemingen over de relatieve gevoeligheid van Bowtie en Maq zijn hier van toepassing.
Leeslengte en prestaties
naarmate de sequentietechnologie verbetert, groeien de leeslengtes verder dan de 30-bp tot 50-bp die tegenwoordig in openbare databases algemeen wordt gezien., Bowtie, Maq, en SOAP ondersteuning leest van lengtes tot 1.024, 63, en 60 bp, respectievelijk, en MAQ versies 0.7.0 en later ondersteuning leeslengtes tot 127 bp. Tabel 3 toont prestatie resultaten wanneer de drie instrumenten elk worden gebruikt om drie sets van 2 M untrimmed leest, een 36-bp set, een 50-bp set en een 76-bp set, op het menselijk genoom op het serverplatform af te stemmen. Elke set van 2 M wordt willekeurig bemonsterd uit een grotere set (NCBI Short Read Archive: SRR003084 voor 36-bp, SRR003092 voor 50-bp, SRR003196 voor 76-bp)., De meetwaarden werden zodanig bemonsterd dat de drie sets van 2 M een uniform foutenpercentage per basis hebben, berekend op basis van de Phred-kwaliteiten per basis. Alle lezingen gaan door Maq ‘ s ‘catfilter’.
Bowtie wordt zowel in de MAQ-achtige standaardmodus als in de SOAP-achtige ‘-v 2’ – modus uitgevoerd. Bowtie krijgt ook de ‘-z’ optie om ervoor te zorgen dat alleen de forward of mirror index in het geheugen aanwezig is. Maq v0. 7.1 werd gebruikt in plaats van Maq v0.6.6 voor de 76-bp set omdat v0.6.,6 kan niet langer dan 63 bp uitlijnen. SOAP werd niet uitgevoerd op de 76-bp set omdat het niet ondersteunt leest langer dan 60 bp.
de resultaten tonen aan dat het algoritme van Maq over het algemeen beter schaalt naar langere leeslengtes dan Bowtie of SOAP. Echter, Bowtie in SOAP-achtige ‘- v 2’ modus schaalt ook heel goed. Bowtie in zijn standaard Maq-achtige modus schaalt goed van 36-bp naar 50-bp leest, maar is aanzienlijk langzamer voor 76-bp leest, hoewel het nog steeds meer dan een orde van grootte sneller dan Maq.,
parallelle prestaties
uitlijning kan worden parallelliseerd door het verdelen van reads over gelijktijdige zoek threads. Bowtie stelt de gebruiker in staat om een gewenst aantal threads op te geven (optie-p); Bowtie lanceert vervolgens het opgegeven aantal threads met behulp van de pthreads-bibliotheek. Bowtie threads synchroniseren met elkaar bij het ophalen van reads, het uitvoeren van resultaten, het schakelen tussen indices en het uitvoeren van verschillende vormen van wereldwijde boekhouding, zoals het markeren van een read als ‘done’., Anders zijn threads vrij om parallel te werken, waardoor de uitlijning op computers met meerdere processorkernen aanzienlijk wordt versneld. Het geheugenbeeld van de index wordt gedeeld door alle threads, zodat de footprint niet substantieel toeneemt wanneer meerdere threads worden gebruikt. Tabel 4 toont prestatieresultaten voor het uitvoeren van Bowtie v0. 9.6 op de vier-core server met één, twee en vier threads.,
Index building
Bowtie maakt gebruik van een flexibel indexeringsalgoritme dat kan worden geconfigureerd om af te wisselen tussen geheugengebruik en looptijd. Tabel 5 illustreert deze afweging bij het indexeren van het gehele menselijke referentiegenoom (NCBI build 36.3, contigs). Runs werden uitgevoerd op het server platform. De indexer werd vier keer uitgevoerd met verschillende bovengrens voor geheugengebruik.,
de gerapporteerde tijden zijn gunstig vergeleken met uitlijningstijden van concurrerende tools die indexeren tijdens uitlijning uitvoeren. Minder dan 5 uur is nodig voor Bowtie om zowel te bouwen en query een whole-human index met 8.84 miljoen reads uit het 1.000 Genome project (NCBI Short Read Archive: SRR001115) op een server, meer dan zes keer sneller dan de equivalente MAQ run., De onderste rij illustreert dat de Bowtie indexer, met de juiste argumenten, geheugen-efficiënt genoeg is om te draaien op een typisch werkstation met 2 GB RAM. Aanvullend gegevensbestand 1 (Aanvullende discussies 3 en 4) legt het algoritme en de inhoud van de resulterende index.
Software
Bowtie is geschreven in C++ en maakt gebruik van de seqan-bibliotheek . De converter naar het MAQ mapping formaat maakt gebruik van code van Maq.