Bowtie indekser referanse genom ved hjelp av en ordning basert på Burrows-Hjuling transform (BWT) og FM-indeksen . En Bowtie indeks for menneskelig genom passer 2,2 GB på harddisken, og har et minne fotavtrykk av så lite som 1.3 GB ved justering tid, slik at det å bli avhørt på en arbeidsstasjon med under 2 GB RAM.,
Den vanligste metoden for å søke i en FM-indeksen er den eksakte-matchende algoritme av Ferragina og Manzini . Bowtie ikke bare vedta denne algoritmen fordi eksakt matching tillater ikke for sekvensering feil eller genetiske variasjoner. Vi introduserer to romanen utvidelser som gjør teknikken som gjelder for korte lese-justering: en kvalitetsbevisst backtracking algoritme som gjør det mulig samsvarer ikke og tjenester av høy kvalitet justeringer, og ‘double indeksering», en strategi for å unngå overdreven backtracking., Den Bowtie aligner følger en politikk som ligner Maq er, i at det tillater et lite antall samsvarer ikke i høy kvalitet slutten av hver leser, og det setter en øvre grense for summen av kvalitet verdier på feilaktige justering posisjoner.
Burrows-Hjuling indeksering
BWT er en reversibel permutasjon av tegn i en tekst. Selv om det opprinnelig ble utviklet innen rammen av data komprimering, BWT-basert indeksering kan store tekster til å søke effektivt i et lite minne fotavtrykk., Det har vært anvendt bioinformatikk programmer, inkludert oligomer telle , hel-genom justering , flislegging microarray probe design , og Smith-Waterman justering til et menneske-størrelse referanse .
Det Hulene-Hjuling transformasjon av en tekst T, BWT(T), er bygget opp som følger. Tegnet $ legges til T, der $ er ikke i T og er lexicographically mindre enn alle tegn i T. Burrows-Hjuling-matrisen til T er konstruert som en matrise som rader består av alle syklisk rotasjoner av T$. Radene er deretter sortert lexicographically., BWT(T) er en sekvens av tegn i kolonnen lengst til høyre av de Burrows-Hjuling matrise (Figur 1a). BWT(T) har samme lengde som den opprinnelige teksten T.
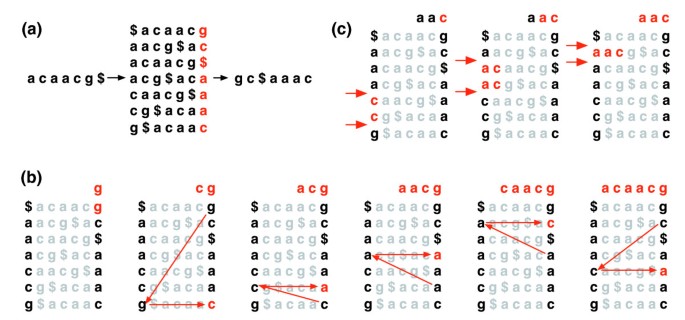
Burrows-Hjuling transform. (a) Burrows-Hjuling matrix og transformasjon for ‘acaacg’. (b) tiltak som er iverksatt av EXACTMATCH å identifisere omfanget av rader, og dermed sett med referanse suffikser, prefikset med «aac’., (c) UNPERMUTE gjentatte ganger gjelder det siste først (LF) kartlegging for å gjenopprette den opprinnelige teksten (i rødt på den øverste linjen) fra Burrows-Hjuling transform (i svart i kolonnen lengst til høyre).
Denne matrisen har en egenskap som heter «siste først (LF) mapping’. Ith forekomst av tegnet X i den siste kolonnen tilsvarer samme tegn i teksten som ith forekomster av X i den første kolonnen. Denne egenskapen ligger til grunn for algoritmer som bruker BWT-indeksen til å navigere eller søke i teksten., Figur 1b viser UNPERMUTE, en algoritme som gjelder LF kartlegging gjentatte ganger for å re-opprette T fra BWT(T).
LF kartlegging er også brukt i eksakt matching. Fordi matrix er sortert lexicographically, rader som begynner med en gitt sekvens dukker opp fortløpende. I en serie av trinn, EXACTMATCH algoritmen (Figur 1c) beregner omfanget av matrix rader som begynner med suksessivt lenger suffikser for spørringen. På hvert trinn, størrelsen på husholdningen, enten krymper eller forblir den samme., Når algoritmen er ferdig, rader som begynner med S0 (hele spørringen) tilsvarer nøyaktig forekomster av søkeordet i teksten. Hvis området er tom, vises teksten ikke inneholder spørringen. UNPERMUTE er knyttet til Burrows og Wheeler og EXACTMATCH å Ferragina og Manzini . Se Flere data fil 1 (Utfyllende Diskusjon 1) for detaljer.
Søk etter eksakt justeringer
EXACTMATCH er ikke nok for korte les justering fordi justeringer kan inneholde samsvarer ikke, noe som kan være grunn til sekvensering feil, ekte forskjeller mellom referanse-og spørring organismer, eller begge deler., Vi innføre en justering algoritme som utfører en tilbakesporing søket for å raskt å finne justeringer som tilfredsstiller spesifiserte justering for personvern. Hvert tegn i en leser har en numerisk kvalitet verdi, med lavere verdier indikerer en høyere sannsynlighet for en sekvensering feil. Våre justering retningslinjene tillater et begrenset antall samsvarer ikke og foretrekker justeringer der summen av kvalitet verdier på alle avvikende posisjoner er lav.
søk foregår på samme måte som EXACTMATCH, beregning av matrix-områder for suksessivt lenger spørring suffikser., Hvis området blir tomme (et suffiks som ikke forekommer i teksten), deretter algoritmen kan velge en allerede matchet søket posisjon og erstatte en annen base der, å innføre et misforhold i plasseringen. Den EXACTMATCH søk på igjen fra like etter erstattet posisjon. Algoritmen velger bare de erstatninger som er i samsvar med justering for personvern og som gir et endret suffiks som skjer minst en gang i teksten. Hvis det er flere som kandidat byttet posisjoner, så grådig algoritme velger en posisjon med en minimal kvalitet verdi.,
Backtracking scenarier spille seg ut innenfor rammen av en stabel struktur som vokser når en ny erstatning er innført og krymper når aligner avviser alle kandidaten justeringer for innbytter for tiden på stakken. Se Figur 2 for en illustrasjon av hvordan søk kan fortsette.
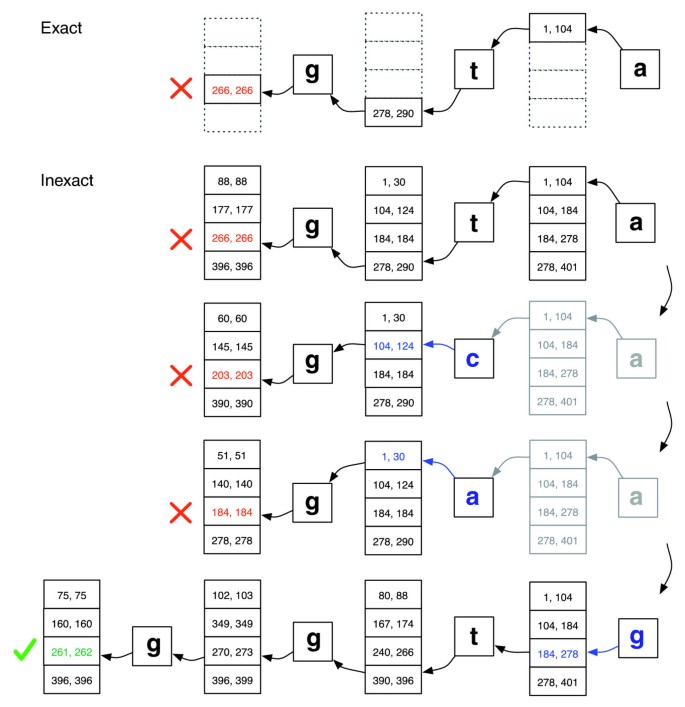
Eksakt matching mot inexact justering., Illustrasjon av hvordan EXACTMATCH (øverst) og Bowtie er aligner (nederst) fortsett når det ikke er noen eksakt match for spørring ‘ggta», men det er en ett-mismatch justering når ‘a’ erstattes med ‘g’. Eske parene av tall som representerer områder av matrix rader som begynner med endelsen observert opp til det punktet. En rød X markerer hvor algoritmen møter et tomt område og enten avbryter (som i EXACTMATCH) eller backtracks (som i inexact algoritme). En grønn merker hvor algoritmen finner en nonempty utvalg avgrense en eller flere forekomster av en rapporterbar justering for spørring.,
kort sagt, Bowtie utfører en kvalitetsbevisst, grådige, randomisert, dybde-først søk gjennom plass av mulige justeringer. Hvis en gyldig justering eksisterer, så Bowtie vil finne det (i henhold til backtrack tak diskutert i neste kapittel). Fordi søket er grådige, den første gyldig justering oppstått ved Bowtie vil ikke nødvendigvis være den «beste» i form av antall samsvarer ikke eller i form av kvalitet., Brukeren kan instruere Bowtie å fortsette å søke til det kan bevises at en justering det rapporter som er ‘best’ i form av antall samsvarer ikke (ved å bruke valget –best). I vår erfaring, er denne modusen er to til tre ganger langsommere enn standard-modus. Vi forventer at de raskere standard-modus vil bli foretrukket for store re-sekvensering av prosjekter.
brukeren kan også velge Bowtie å rapportere alle justeringer opp til et bestemt antall (alternativ -k) eller alle justeringer er ingen begrensning på antall (alternativ a) for en gitt les., Hvis du, i løpet av sitt søk Bowtie finner N mulige justeringer for et gitt sett av innbytter, men brukeren har bedt om bare K justeringer der K < N, Bowtie vil rapportere K av N justeringer tilfeldig valgt. Vær oppmerksom på at disse innstillingene kan være mye lavere enn standard. I vår erfaring, for eksempel, -k 1 er mer enn dobbelt så raskt som -k 2.
Overdreven backtracking
aligner som er beskrevet så langt kan, i noen tilfeller, møte-sekvenser som forårsaker overdreven backtracking., Dette skjer når aligner tilbringer det meste av sin innsats fruitlessly å spore tilbake til posisjoner nær 3′ – enden av spørringen. Bowtie reduserer overdreven backtracking med romanen teknikk av «dobbel indeksering’. To indekser av genom er opprettet: én som inneholder BWT av genom, kalt «forward» – indeksen, og et annet som inneholder BWT av genom med sin karakter sekvens reverseres (ikke omvendt supplert) kalt ‘speil’ indeks. For å se hvordan dette hjelper, bør du vurdere en tilsvarende politikk som gjør at en mismatch i justeringen., En gyldig tråd med en mismatch faller i en av to tilfeller i henhold til hvor halvparten av lese inneholder samsvar. Bowtie foregår i to faser tilsvarende de to tilfeller. Fase 1 laster frem indeks i minnet, og påkaller aligner med den begrensning at det ikke erstatning på stillinger i spørringens høyre halvdel. Fase 2 bruker speilet indeks og påkaller aligner på reversert spørring, med de begrensninger som det aligner kan ikke erstatte på stillinger i reversert spørringens høyre halvdel (den opprinnelige spørringen venstre halvdel)., Begrensninger på å spore tilbake til den høyre halvdelen hindre overdreven backtracking, mens bruk av to faser og to indekser opprettholder full følsomhet.
det er Dessverre ikke mulig å unngå overdreven backtracking fullt når justeringene er tillatt å ha to eller flere samsvarer ikke. I våre eksperimenter, har vi observert at overdreven backtracking er betydelige bare når en leser har mange lav-kvalitet stillinger, og ikke plasser eller passer dårlig til referanse., I disse tilfeller kan utløse i overkant av 200 backtracks per lese fordi det er mange lovlige kombinasjoner av lav kvalitet posisjoner på å bli utforsket før alle muligheter er uttømt. Vi redusere denne kostnaden ved å håndheve en grense på antall backtracks tillatt før et søk er avsluttet (standard: 125). Grensen hindrer noen legitim, lav kvalitet tilnærmingene blir rapportert, men vi forventer at dette er en ønskelig trade-off for de fleste bruksområder.,
Faset Maq-som søk
Bowtie tillater brukeren å velge antallet samsvarer ikke tillatt (standard: to) i høy kvalitet slutten av en lese (standard: de første 28 baser) så vel som maksimal akseptabel kvalitet avstand av samlet justering (standard: 70). Kvalitet verdier er antatt å følge definisjonen i PHRED , der p er sannsynligheten for feil og Q = -10log p.
Både lese og dens omvendt utfylle er kandidater for justering til referansen. For å tydeliggjøre denne diskusjonen vurderer bare frem orientering., Se Flere data fil 1 (Utfyllende Diskusjon 2) for en forklaring av hvordan omvendt utfylle er innarbeidet.
De første 28 baser på høy kvalitet slutten av lese-og er kalt «frø». Frøet består av to halvdeler: 14 bp på høy kvalitet slutten (vanligvis 5′ – enden) og 14 bp på lav kvalitet slutten, kalt ‘hi-halvparten» og «lo-halv’, henholdsvis., Forutsatt standard policy (to samsvarer ikke tillatt i frø), en rapporterbar justeringen vil falle inn under en av fire tilfeller: ingen samsvarer ikke i frø (sak 1); ikke samsvarer ikke i hi-to, ett eller to samsvarer ikke i lo-halvparten (tilfelle 2); ikke samsvarer ikke i lo-to, ett eller to samsvarer ikke i hi-halvparten (tilfelle 3), og en mismatch i hi-halv, en mismatch i lo-halvparten (case 4).
Alle tilfeller tillate at et hvilket som helst antall samsvarer ikke i nonseed del av lese-og i alle tilfeller er også underlagt kvalitet avstand tvang.,
Bowtie algoritmen består av tre faser som veksler mellom å bruke den fremover og speil indekser, som illustrert i Figur 3. Fase 1 bruker speilet indeks og påkaller aligner å finne justeringer for tilfeller 1 og 2. Fase 2 og 3 samarbeide for å finne justeringer for tilfelle 3: Fase 2 finner delvis justeringer med samsvarer ikke bare i hi-to og fase 3 forsøk på å utvide de delvis justeringer i full justeringer. Til slutt, fase 3 påkaller aligner å finne justeringer for case 4.,

De tre fasene av Bowtie algoritme for Maq-lignende politikk. En tre-fase tilnærming finner justeringer for to-mismatch tilfeller 1 til 4, mens minimere backtracking. Fase 1 bruker speilet indeks og påkaller aligner å finne justeringer for tilfeller 1 og 2. Fase 2 og 3 samarbeide for å finne justeringer for tilfelle 3: Fase 2 finner delvis justeringer med samsvarer ikke bare i hi-halvparten, og fase 3 forsøk på å utvide de delvis justeringer i full justeringer., Til slutt, fase 3 påkaller aligner å finne justeringer for case 4.
resultater
Vi har vurdert resultatene av Bowtie ved hjelp av lyder fra 1,000 Genomer prosjektet pilot (Nasjonalt Senter for Bioteknologi Informasjon Korte Les Arkiv:SRR001115). Totalt 8.84 millioner leser, om ett kjørefelt av data fra en Illumina instrument, var trimmet til 35 bp og justert i forhold til den menneskelige referanse genom . Med mindre annet er spesifisert, lese data er ikke filtrert eller endret (i tillegg til trimming) fra hvordan de ser ut i arkivet., Dette fører til ca 70% til 75% av lyder justere et sted til genom. I vår erfaring, dette er typisk for raw-data fra arkivet. Mer aggressiv filtrering fører til høyere justering priser og raskere justering.
Alle kjøringer ble utført på en enkelt CPU. Bowtie speedups ble beregnet som forholdet vegg-klokke justering ganger. Både vegg-klokke og CPU-tid er gitt for å vise at input/output last og CPU påstand ikke er viktige faktorer.
Den tiden som kreves for å bygge Bowtie indeksen var ikke inkludert i Bowtie kjører ganger., I motsetning til konkurrerende verktøy, Bowtie kan bruke en pre-beregnet indeks for referanse genom over mange justeringen går. Vi regner med at de fleste brukere vil bare laste ned slike indekser fra en offentlig depotet. Den Bowtie nettstedet gir indekser for aktuelle bygger på det menneskelige, sjimpanse, mus, hund, rotte, og Arabidopsis thaliana genomer, så vel som mange andre.
Resultater ble oppnådd på to maskinvare plattformer: en arbeidsstasjon med 2,4 GHz Intel Core 2-prosessor og 2 GB RAM, og en stor-minne server med fire kjerner på 2,4 GHz AMD Opteron-prosessor og 32 GB RAM., Disse er merket ‘PC’ og ‘server’, henholdsvis. Både PC og server kjører Red Hat Enterprise Linux SOM utgivelse 4.
forhold til SÅPE og Maq
Maq er et populært aligner som er blant de raskeste konkurrerende open source verktøy for å samkjøre millioner av Illumina leser av det menneskelige genom. SÅPE er et annet verktøy med åpen kildekode som har blitt rapportert og brukes i kort-lese-prosjekter .
Tabell 1 presenterer resultatene og følsomhet av Bowtie v0.9.6, SÅPE v1.10, og Maq v0.6.6. SÅPE kan ikke kjøres på PC-en fordi SÅPE minne fotavtrykk overstiger PC-en er fysisk minne. Den ‘såpe.,contig’ versjon av SÅPE binære ble brukt. For sammenligning med SÅPE, Bowtie ble startet med ‘-v 2′ for å etterligne SÅPE er standard matchende politikk (som tillater opp til to samsvarer ikke i justering og ser bort fra kvalitet verdier), og med «–maxns 5’ for å simulere SÅPE er standard policy med å filtrere ut lyder med fem eller flere manglende tillit baser. For Maq sammenligningen Bowtie kjøre med sin standard for personvern, som etterligner Maq er standard policy la opp til to samsvarer ikke i første 28 baser og håndheve en samlet grense på 70 på summen av kvalitet verdier på alle feilaktige les posisjoner., For å gjøre Bowtie minne fotavtrykk mer sammenlignbare med Maq er Bowtie startes med » z » – alternativet i alle eksperimenter for å sikre at bare den frem eller speil-indeksen er bosatt i minnet på en gang.
antall lesninger justert indikerer at SÅPE (67.3%) og Bowtie -v 2 (67.4%) har sammenlignbare følsomhet. Av leser justert ved enten SÅPE eller Bowtie, 99.7% ble justert både på 0,2% ble justert ved Bowtie, men ikke SÅPE, og 0,1% var på linje med SÅPE, men ikke Bowtie. Maq (74.7%) og Bowtie (71.9%) har også omtrent sammenlignbare følsomhet, selv om Bowtie henger med 2,8%., Av leser justert ved enten Maq eller Bowtie, 96.0% ble justert av begge, 0.1% ble justert ved Bowtie, men ikke Maq, og 3,9% var på linje med Maq men ikke Bowtie. Av leser kartlagt med Maq men ikke Bowtie, nesten alle er på grunn av en fleksibilitet i Maq er justering algoritme som gjør noen justeringer for å ha tre samsvarer ikke i frøet. Resten av lyder kartlagt med Maq men ikke Bowtie er grunn til å Bowtie er backtracking tak.
Maq dokumentasjon nevner som leser som inneholder ‘poly-Et-artefakter’ kan svekke Maq ytelse., Tabell 2 presenterer ytelse og følsomhet av Bowtie og Maq når de leser sett er filtrert med Maq ‘s » catfilter’ – kommandoen til å eliminere poly-Et-artefakter. Filter eliminerer 438,145 ut av 8,839,010 leser. Andre eksperimentelle parametere er identiske med de av forsøkene i Tabell 1, og det samme observasjoner om den relative følsomhet for Bowtie og Maq gjelder her.
Les lengde og ytelse
Som sekvensering teknologien forbedres, lese lengder er økende utover 30-bp 50-bp vanligvis sett i offentlige databaser i dag., Bowtie, Maq, og SÅPE støtte leser av lengder opptil 1024, 63 og 60 bp, henholdsvis, og Maq versjoner 0.7.0 og senere støtter lese lengder opp til 127 bp. Tabell 3 viser resultatene når de tre verktøyene er hver som brukes til å justere tre sett av 2 M ikke-tilklippet leser, en 36-bp sett, en 50-bp sett og en 76-bp sett, for det menneskelige genom på server plattform. Hvert sett av 2 M er tilfeldig trukket fra en større sett (NCBI Korte Les Arkiv: SRR003084 for 36-bp, SRR003092 for 50-bp, SRR003196 for 76-bp)., Lyder ble samplet slik at de tre sett med 2 M ha uniform per-base error rate, som er beregnet fra per-base Phred kvaliteter. Alle leser passere gjennom Maq ‘s » catfilter’.
Bowtie kjøres både i sin Maq-som standard modus og i sin SÅPE-liker ‘-v 2’ – modus. Bowtie er også gitt ‘-z’ alternativ for å sikre at bare den frem eller speil-indeksen er bosatt i minnet på en gang. Maq v0.7.1 ble brukt i stedet for Maq v0.6.6 for den 76-bp sett fordi v0.6.,6 kan ikke justere leser lenger enn 63 bp. SÅPE var ikke kjøre på 76-bp sett fordi det støtter ikke leser lenger enn 60 bp.
resultatene viser at Maq algoritme skalaer bedre samlet til lenger lese lengder enn Bowtie eller SÅPE. Imidlertid, Bowtie i SÅPE-liker ‘-v 2’ – modus også skalerer svært godt. Bowtie i standard Maq-modus som skalerer godt fra 36-bp 50-bp lyder, men er vesentlig lavere for 76-bp-leser, selv om det fortsatt er mer enn en størrelsesorden raskere enn Maq.,
Parallell ytelse
Justering kan være parallelized ved å distribuere leser over samtidige søk tråder. Bowtie lar brukeren angi en ønsket antall tråder (alternativ -p), Bowtie deretter starter det angitte antall tråder ved hjelp av pthreads bibliotek. Bowtie tråder synkronisere seg med hverandre når du henter leser, gi ut resultatene, kan bytte mellom indekser, og utføre ulike former for global bokføring, som for eksempel merking en lest som «fullført»., Ellers, tråder er gratis å operere parallelt, vesentlig raskere justering på datamaskiner med flere prosessorkjerner. Minnet bilde av indeksen er delt av alle tråder, og så fotavtrykket ikke øker vesentlig når flere tråder blir brukt. Tabell 4 viser resultatene for å kjøre Bowtie v0.9.6 på fire-core-server med ett, to og fire tråder.,
– Indeksen bygger
Bowtie bruker en fleksibel indeksering algoritme som kan være konfigurert til å trade off mellom bruk av minne og kjører tid. Tabell 5 illustrerer denne trade-off når indeksering hele den menneskelige referanse genom (NCBI bygge 36.3, contigs). Kjøringer ble utført på server plattform. Indeksereren ble kjørt fire ganger med forskjellige øvre grenser på bruk av minne.,
Den rapporterte ganger sammenligne seg med justering på tider av konkurrerende verktøy som utfører indeksering under justeringen. Mindre enn 5 timer er nødvendig for Bowtie å både bygge og spørring et helt menneske-indeksen med 8.84 millioner leser fra 1000 Genome project (NCBI Korte Les Arkiv:SRR001115) på en server, mer enn sixfold raskere enn tilsvarende Maq kjøre., Nederst mest rad illustrerer at Bowtie indeksering, med passende argumenter, er memory-effektiv nok til å kjøre på en vanlig arbeidsstasjon med 2 GB RAM. Ytterligere data fil 1 (Supplerende diskusjoner 3 og 4) forklarer algoritme og innholdet av den resulterende indeks.
– Programvare
Bowtie er skrevet i C++ og bruker SeqAn bibliotek . Omregning til Maq kartlegging formatet bruker koden fra Maq.