
+ å Lære å spille inn og mikse hjemme? Sjekk ut Soundfly anerkjente online kurs på miksing, produksjon, slo lage og mer — abonnement for ubegrenset tilgang.
Det er ikke lenger en hemmelighet at det de gjør-det-selv-ånd i lyd produksjon har økt dramatisk i de siste årene. Er ikke det kult hvor mye kontroll har vi over vår egen musikk i disse dager?,
Hvis du er et soverom produsent som meg, du er sikkert opptatt med å skape litt frisk, kunstnerisk musikk akkurat nå. Men du har trolig innsett at musikk-produksjon kan ofte føles mer som en vitenskap enn en form for kunst til tider. Når det kommer til miksing, forstå hvordan bølgeformer og lyd-frekvenser bidra til den samlede sonic bilde som de kan komme i konflikt eller passe komfortabelt sammen, kan gjøre eller ødelegge din sang.,
Og når det kommer til den menneskelige stemmen, den viktigste musikalske ledelsen av de fleste sjangere av musikk i dag, og ofte er det sentrale punktet i en flott blanding, er det viktig å forstå hvordan disse frekvensene operere. Og det er der EQ kommer inn.
jeg har brukt timer på å blande min egen stemme i mitt hovedprosjekt Unkenny Daler (og jeg får fortsatt trukket opp noen ganger), men jo mer erfaring jeg får mens du produserer, jo mer jeg hører glans og makt kommer gjennom i min vokalspor. Jeg hører også at i løpet av årene, elementer av sløvhet og muddiness har falt bort., Så la oss snakke litt om EQing menneskelig vokal frekvenser. Hvis du vil ha mer hjelp på å produsere store-klingende vokal, ta en gratis forhåndsvisning av våre Moderne Pop Vocal Produksjon kurset til å gå enda dypere.
EQ
for Å produsere en profesjonell sangen fra raw-innspilt lyd spor, equalizer (EQ) er et av de viktigste verktøyene til din disposisjon. Ved avveiningen av større dynamisk oppturer og nedturer i volumet av en kompressor, en EQ er din beste venn når det kommer til å intervenere i frekvensspekteret i detalj., I denne artikkelen, jeg kommer til å bruke en parametrisk EQ som mange har spektral analysatorer som hjelper oss med å visualisere frekvens innhold av lyd svært presist.
For en rask primer på EQ, her er en oversikt fra noen av de beste ingeniørene i New York, fra vår Faders Opp I: Moderne Blanding Teknikker kurs.
Frekvens
Vi representerer frekvens ved hjelp av buede linjer, som for eksempel sinus. Når en sinusformet pendling strekker seg over en hel andre, henviser vi til det som én Hertz (1 Hz). Jo høyere frekvens, jo mer bølger vi vil se per sekund, slik at antall Hertz går opp.,
+ Les mer på Flypaper: «Gjør dynamo kiev og Huset Kattene Male på Samme Frekvens?»
Frekvenser av den Menneskelige Stemme
Når likestille vokal, vi bør huske på at den gjennomsnittlige lengden på stemmebåndene mellom kvinner og menn har en tendens til å variere.
hos kvinner, på ca 15 millimeter, de er i gjennomsnitt ca 5 millimeter kortere enn menns stemmebåndene. Som et resultat, vibrerer de relativt per sekund raskere enn menn gjør, noe som resulterer i en høyere frekvenser. I motsatt fall, lenger stemmebåndene føre til lenger bølge bevegelser per sekund og dermed produsere en dypere lyd.,

De Frekvensene Vi Kan Høre
Det menneskelige øret kan høre på mellom 20 og 20 000 Hz (20 kHz), men det er mest sensitiv for alt som skjer mellom 250 og 5000 Hz.
Under en samtale, er den fundamentale frekvensen av en typisk voksen mann varierer fra 80 til 180 Hz, og at en typisk voksen kvinne fra 165 til 255 Hz. Dermed, hvis vi ser på disse tre bildene, den fundamentale frekvensen av de fleste ytringer faller inn under den nedre kanten av «tale frekvensbåndet.,»
Likevel, vi kan høre det mangler keynotes som for det meste er hørbare for oss, fordi det er nok av de harmoniske serien til stede for å gi våre ører dette inntrykket.
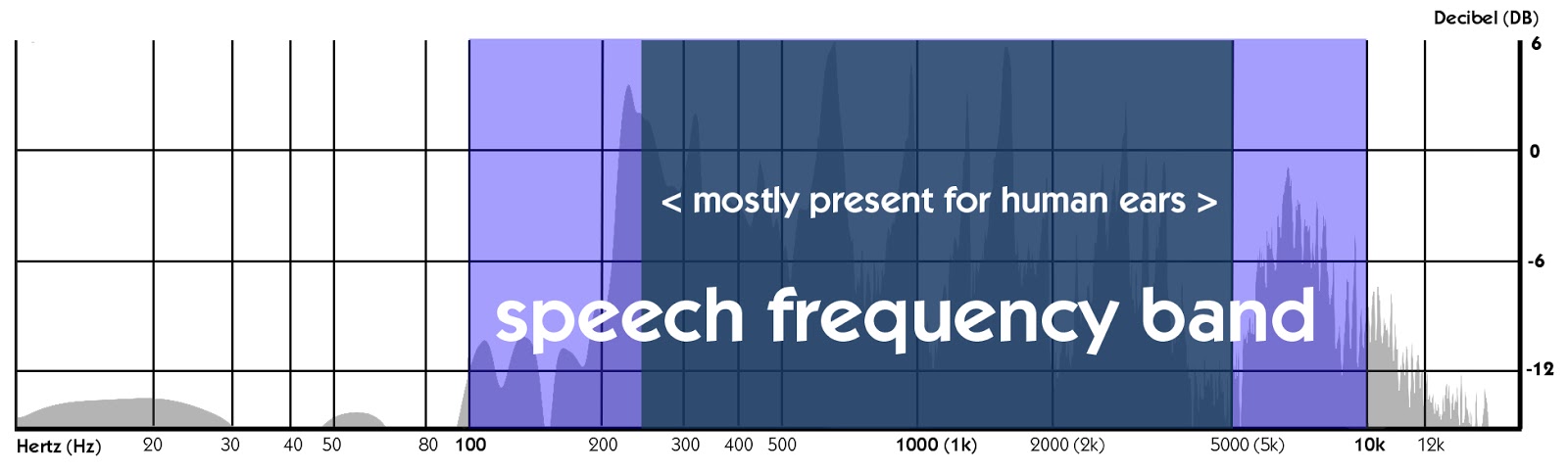
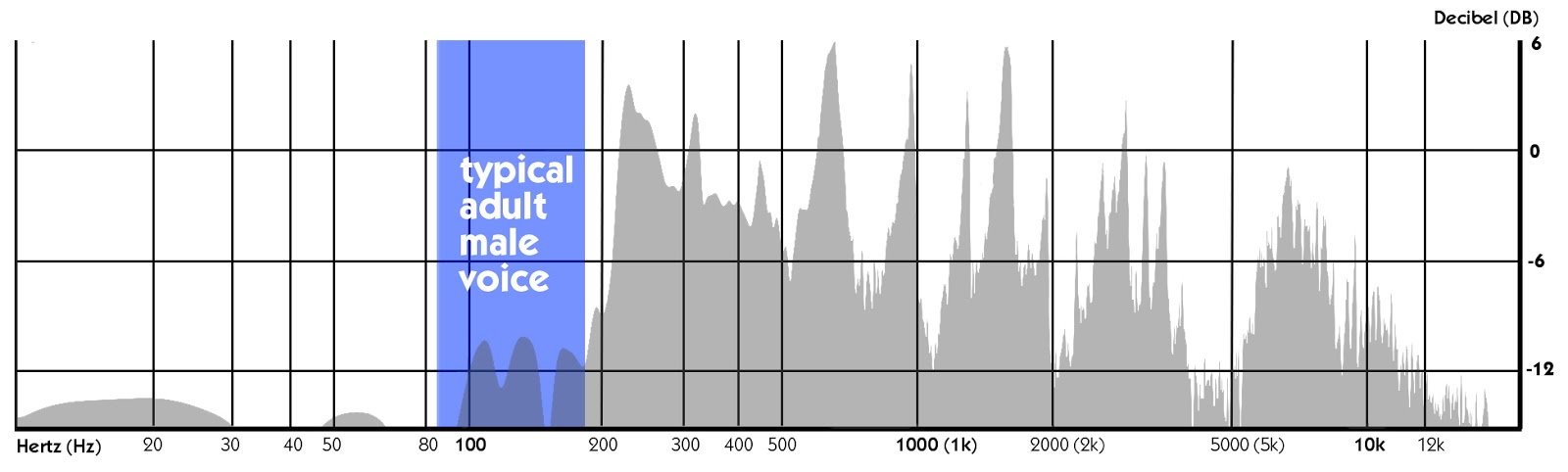
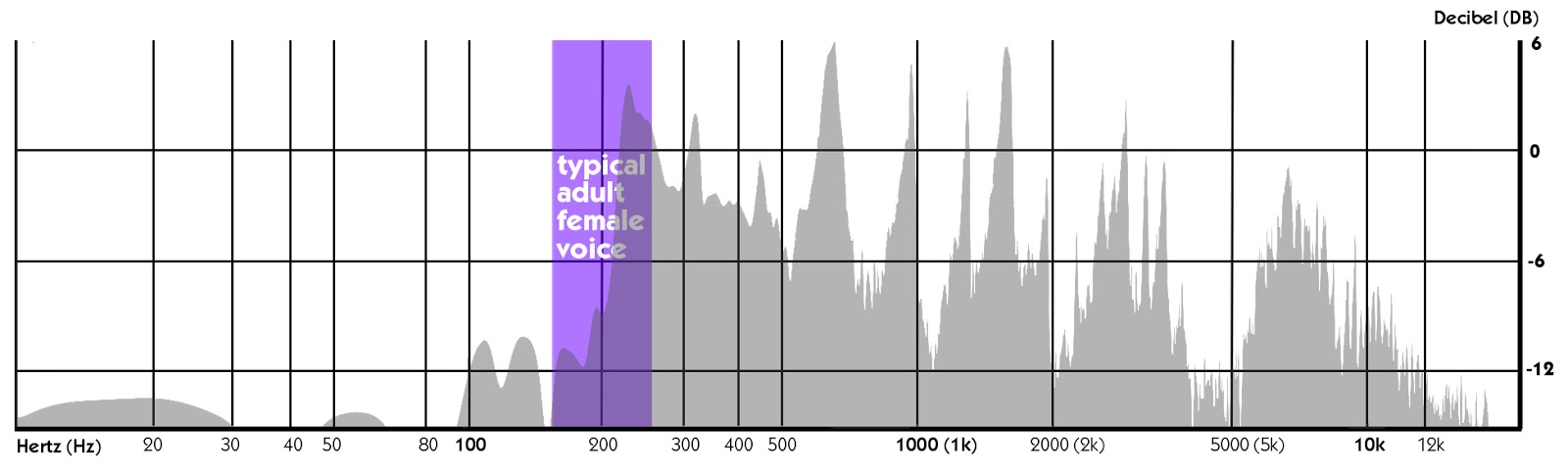
Men alt dette er bare om conversational tale og snakke, så hvordan gjør den menneskelige stemme arbeid i musikk? La oss snakke om det i neste avsnitt.
+ Få bedre klingende stemmer med våre Moderne Pop Vocal Produksjon kurs undervist av elektro-pop-artist SIRMA., Hun har jobbet med Akon, Keri Hilson, Illenium, og mange andre. Forhåndsvise kurs for gratis nå.
Hvordan å Profesjonelt EQ Din Vokal
Vel, det handler om nedturer, mellomtoner, og tripler. Når du lytter tilbake til din raw-innspilt vokal spor for første gang før du begynner å blande det, kan du finne lyden av noen ord litt harde, eller tenke, eller for kjedelig å høre. Dette er hvor den art av EQ kommer inn.
Her er noen tips for EQing vokal, og hvordan du kan identifisere hva som er viktig å holde og hva vi skal minimere.,
Bruk en Referanse Spore
Før du begynner å flytte noen knotter eller faders, det er alltid en god idé å lytte til faglig blandet musikk som kan fungere som en anstendig referanse for hva du prøver å gjøre med dine spor. I dette tilfellet, vil du sannsynligvis ønske å bruke noe med en sterk og tilstede vokal-lyd.
(*ikke bruk din favoritt sang for all tid hvis det ikke representerer at lydkvaliteten du ønsker å høre på din egen produksjon.,)
Så snart du finner en passende sang, sette opp vokal spor volumet i din DAW før det er lik volumet av referanse-banen som kommer ut av høyttalerne. På den måten vil din hindre deg fra å bli lurt av energi forskjeller som skyldes ulike lydnivåer.
Kvitte seg med den Buldrende Støy
Hvis du finner en diamant i gjørma, du kan ikke se sin sanne glitrende skjønnhet med en gang. Ville du trenger å bli kvitt den hele jord, sand og støv rundt det første., Mikrofonen registrerer alt som er i front av det, og dessverre, som inneholder massevis av støy (både i stemmen og i rommet). Vi egentlig ønsker å oppnå klarhet og glans — en grunnleggende lyd vi kan endre senere, men vi vil — så vi trenger for å klare av skitt.
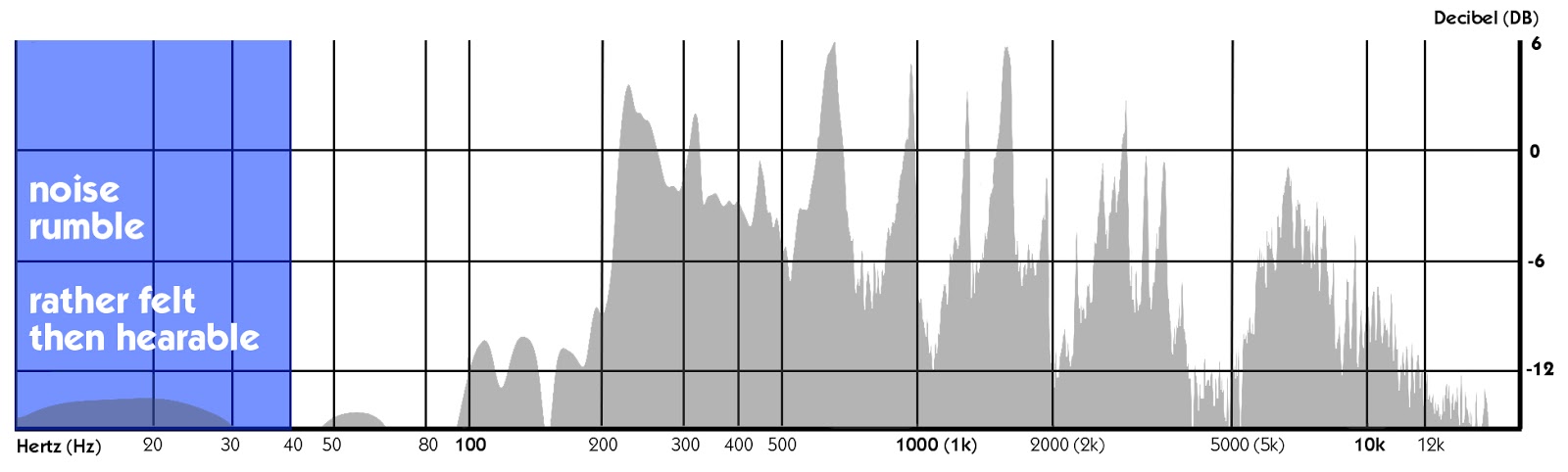
Så den første fungerende trinn av EQing vokal er alltid en grunnleggende «low cut.»Ta bort noe under 40 til 60 Hz. Fordi vi føler heller enn å høre hva som skjer der.
Du trenger ikke å være for forsiktig med de lave frekvensene i et vocal mix., Som du kan se i bildet nedenfor, som jeg tar bort alt under 100 Hz (og noen ganger under 200 Hz for kvinnelig vokal) fordi — som vi nettopp har lært — rundt 100 Hz er der den faktiske «tale frekvensbåndet» begynner.
Selv Ut Energi Humper
Vi har nå fjernet den verste skitten. Men vår verdifull diamant fortsatt kunne bruke litt sliping. Området mellom 200 og 500 Hz kalles «gjørma» frekvensområde. Det er mye av signalet i mitt eksempel ovenfor.
Hvorfor? Fordi de fleste av energi i en menneskelig stemme trer i kraft rundt 250 Hz., Så dette punktet er forretningsvennlig og ligger i nedre mellomtone av våre EQ, det høres veldig mushy rundt det. Ikke vær redd for å redusere få rundt dette området med om lag 5 til 10 desibel (dB) hvis du må.
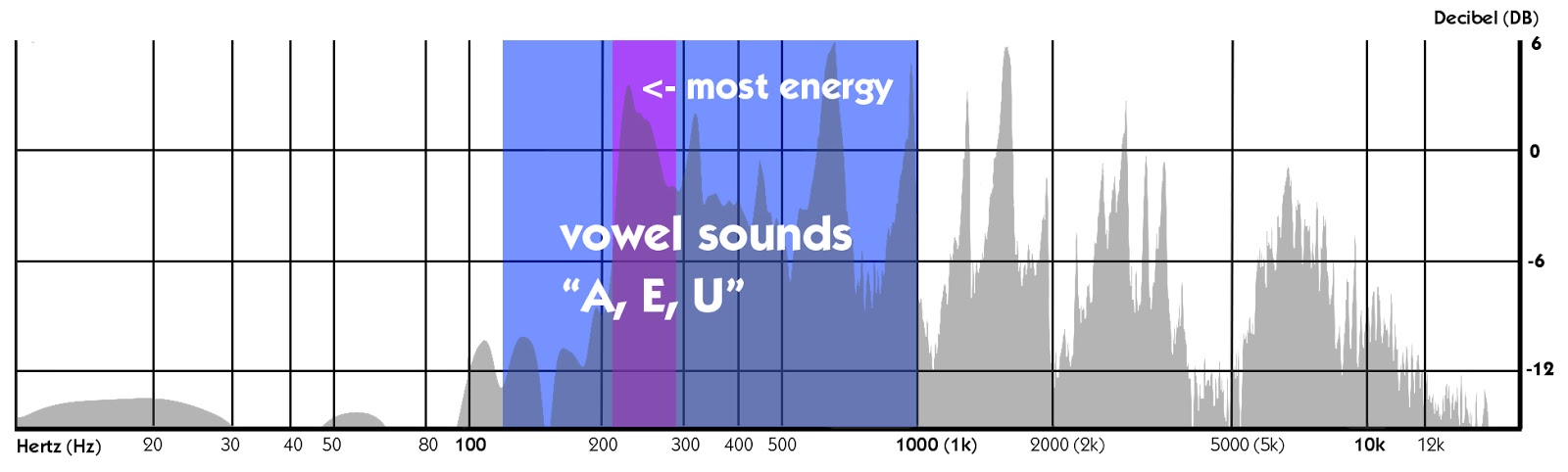
Snakker om energi, mellom 125 og 1000 Hz ligger området der du høre vokalen høres ut som: «en», «e» og «u.»
I eksempelet nedenfor har vi en titt på ordet «tillit.»Vi kan se at de «uh» – lyden er mye større i volum enn angrepet lyden av «tr» og «st.,»Hvis din vokal spor har en mangel på energi, er det antakelig frekvensområdet du bør holde et øye på først.

Nå som vi kan faktisk kjenne den myke overflaten av våre gemstone, la oss endelig starte polering det.
Finesse, eller «Mindre Er Mer»
Fra her vi skal drive litt mer følsomt.
Det er alltid bedre å redusere snarere enn å legge til signalet. Øke volumet av en bestemt frekvens, legger kunstig skapt lyd til vår opprinnelig innspilt spor., Så det er alltid en smartere måte å redusere frekvenser som lyd overflødige i stedet for å legge til ting som ikke var der i utgangspunktet.
Men du bestemmer deg for å behandle en frekvens på slutten, sørge for at din vokal, starter ikke høres uklart og robot igjen. Om du vil legge til eller ta bort for mye, kan du ende opp med en mindre kvalitet signal enn du startet, så mindre tendens til å være mer.
Søk Ubehagelig Områder
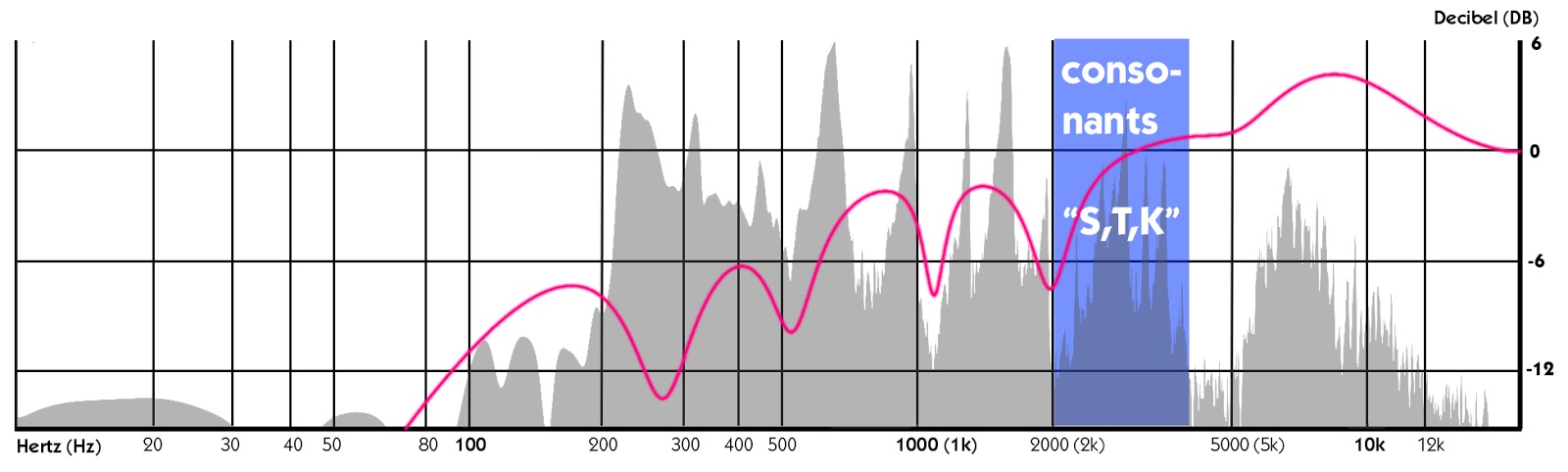
I mitt eksempel, jeg tok ut -7 dB rundt 1 kHz og en annen -7 dB på 2 kHz. Jeg fant vokalen lyden var for spiky 1100 Hz og en konsonant på 2 kH var litt for harde., Hver støy vi uttaler i vår halsen og munnen, eller med vår tunge og lepper, en equalizer viser mellom 2000 og 4000 Hz.
Her kan vi se frekvensen avtrykk av talt bokstaver som «s», «t», og «k» (konsonanter). De skaper en hardere tone, er mye lavere i volum enn vokal lyder, og form døren spekteret av de høye frekvensene. De er også svært viktig bokstaver for å identifisere betydningen av ordene hørbart, så vi trenger å beholde sin klarhet, ellers ord vil miste identitet i dine spor.,
Men hvordan kan vi være sikker på hvor nøyaktig noe som ikke høres tøffe?
Den enkleste måten er å feie frekvenser ved hjelp av en gevinst på om lag 12+ dB, ved hjelp av en super liten «Q» (som definerer filter bredde for frekvens området du ønsker å endre). Bare naviger sakte over høyere frekvens-seksjonen for å se etter de piercing notater, og når du finner problemer med frekvenser, ned-regulere dem til de ikke å skille seg ut for mye lenger.,
Polering for Glans for å Gjøre Vokal Glans
Når du er klar, kan du markere frekvenser fra 5 til 12 kHz. Du finner den mest tilstedeværelse rundt 5 kHz. Men vær forsiktig!
sibilants gjemmer seg rundt 6 til 7 kHz. Sibilants er den hvesende lyder som «s» eller «sh.»Hvis du bruker for mye gain, kan de fort bli svært fremtredende. Vanligvis en De-Esser (en kompressor som chokes disse susende lyder hver gang de dukker opp i en sang) kommer i hendig. Det er en veldig vanlig verktøy for å arbeide med i dette tilfellet.,
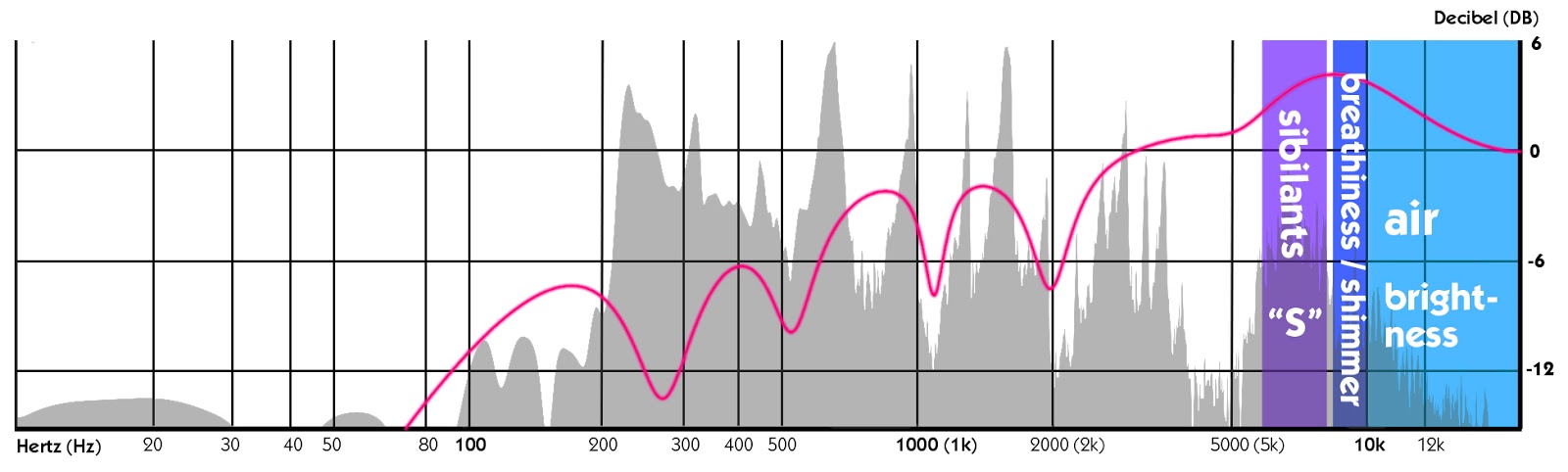
Mellom 8 og 10 kHz, vil du høre breathiness. Øke gevinsten her med bare 3 eller 4 dB vil la vokal virke litt nærmere og gjøre dem skinne gjennom bedre.
til Slutt vil du finne enda mer lysstyrke og en følelse av luft mellom 10 og 15 kHz. Jeg pleier å prøve å utjevne denne delen litt ned som det noen ganger inneholder smekke og svelge lyder.
Sammenlign
til Slutt, omgå dine parametrisk EQ for å sammenligne effekten med råstoff for å få et «før og etter» inntrykk. Hva en forskjell, ikke sant?,
Nå gå tilbake til å sammenligne utlignet vokal spor med vokal av din referanse spor, og avgjøre om du er fornøyd med resultatet. Sesongen til din smak.
stopper ikke her!
Få tilgang til hundrevis av timer miksing, lyd produksjon, vokal opptak, slo lage, og så mye mer, med Soundfly er dybde-og online-kurs, inkludert Avansert Blanding Teknikker og Moderne Pop Vocal Produksjon. Abonnere på ubegrenset tilgang her.
– >
meld deg på her for Soundfly ukentlige nyhetsbrev.,

Kenneth Estrada y Santiago
Kenneth Estrada y Santiago er en produsent, låtskriver og innhold skaperen, som er basert i Berlin, Tyskland. I sin YouTube-kanal SHOEGAZER han deler musikk tutorials, utstyr anmeldelser og utfører sin musikk med innovative teknologiske verktøy i det 21. århundre. Innenfor sitt solo-prosjekt Unkenny Daler, han slipper musikk på Bandcamp og Spotify.