Bowtie 인덱스에 참조 게놈을 사용하여 체계 기반에서 굴 륜 변환(BWT)및 FM index. Bowtie 지수를 위한 인간 게놈 적 2.2GB 디스크에 있는 메모리 용량의 한 작은 1.3GB 정렬하는 시간을 할 수 있도록,쿼리에는 워크스테이션에서 2GB RAM.,
FM 인덱스에서 검색하는 일반적인 방법은 Ferragina 와 Manzini 의 정확한 일치 알고리즘입니다. Bowtie 는 정확한 일치가 시퀀싱 오류 또는 유전 적 변이를 허용하지 않기 때문에 단순히이 알고리즘을 채택하지 않습니다. 우리는 두 개의 새로운 확장자를 만드는 기법을 적용하여 짧은 읽기 정렬:품질-인식 역행 알고리즘을 허용하는 불일치하고 호의 높은 품질의 선형;이블 indexing’전략을 방지하는 과도한 되돌아., 리얼라이너를 다음과와 유사한 정책을 Maq’s 는 점에서,그것은 소수의 불일치에서 고품질의 읽기,그리고 그것은 장소에 상한 합의 품질 값이 일치하지 않는 정렬 위치.
Burrows-Wheeler 인덱싱
BWT 는 텍스트의 문자를 뒤집을 수있는 순열입니다. 하지만 원래 개발의 컨텍스트 내에서 데이터 압축,BWT 기반 인덱싱 할 수 있습 큰 텍스트 검색에 효율적으로 작은 메모리 용량., 가 적용하는 생물정보학 응용 프로그램을 포함,올리고 계산,전체 게놈 정렬,타일 microarray 프로브 설계에는,스미스-워터 정렬하는 인간 크기의 참조.
텍스트 T,BWT(T)의 Burrows-Wheeler 변환은 다음과 같이 구성됩니다. 문$에 추가되 T,어디$지 않 T 고 따라보다 적은 모든 자에 T.Burrows-Wheeler 의 행렬 T 로 구성되어 매트릭스는 그의 행성의 모든 순환의 회전 T$. 그런 다음 행이 사전 순으로 정렬됩니다., BWT(T)는 Burrows-Wheeler 행렬의 가장 오른쪽 열에있는 문자 시퀀스입니다(그림 1a). BWT(T)은 동일한 길이로 원래의 텍스트 T.
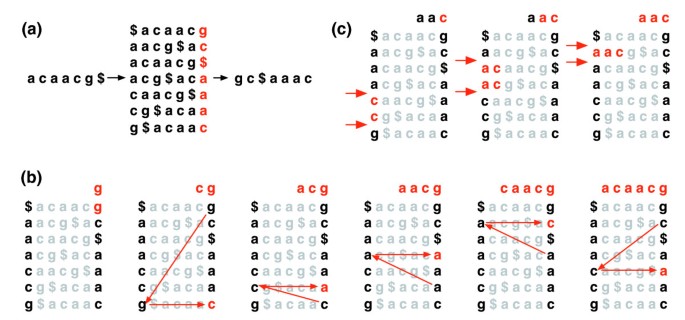
Burrows-Wheeler 변형시킵니다. (a)’acaacg’에 대한 Burrows-Wheeler 매트릭스 및 변환. (b)행의 범위를 식별하기 위해 EXACTMATCH 에 의해 취해진 단계,따라서’aac’접두사가 붙은 참조 접미사 세트., (c)UNPERMUTE 반복적으로 적용되는 지난 첫(LF)매핑을 복구하는 원래의 텍스트(빨간색 상단에 선)에서 Burrows-Wheeler 변환(블랙에서 가장 오른쪽 column).
이 매트릭스에는’last first(LF)매핑’이라는 속성이 있습니다. 마지막 열의 문자 X 의 i 번째 발생은 첫 번째 열의 X 의 i 번째 발생과 동일한 텍스트 문자에 해당합니다. 이 속성은 bwt 인덱스를 사용하여 텍스트를 탐색하거나 검색하는 알고리즘의 기초가됩니다., 그림 1b 는 LF 매핑을 반복적으로 적용하여 BWT(T)에서 T 를 다시 만드는 알고리즘 인 UNPERMUTE 를 보여줍니다.
lf 매핑은 정확한 일치에도 사용됩니다. 행렬은 사전 순으로 정렬되므로 주어진 시퀀스로 시작하는 행이 연속적으로 나타납니다. 일련의 단계에서 EXACTMATCH 알고리즘(그림 1c)은 쿼리의 연속적으로 더 긴 접미사로 시작하는 행렬 행의 범위를 계산합니다. 각 단계에서 범위의 크기가 줄어들거나 동일하게 유지됩니다., 알고리즘이 완료되면 s0(전체 쿼리)으로 시작하는 행이 텍스트에서 쿼리의 정확한 발생에 해당합니다. 범위가 비어 있으면 텍스트에 쿼리가 포함되지 않습니다. UNPERMUTE 는 Burrows 와 Wheeler 와 EXACTMATCH 에 기인합니다.Ferragina 와 Manzini 에게. 자세한 내용은 추가 데이터 파일 1(보충 토론 1)을 참조하십시오.
검색에 대한 부정확한 선형
EXACTMATCH 부족에 대한 짧은 읽기 정렬하기 때문에 정렬을 포함할 수 있습 불일치로 인해 수 있습니다 시퀀싱 오류를,정품 사이의 차이점을 참조 및 쿼리를 유기체입니다., 지정된 정렬 정책을 만족하는 정렬을 신속하게 찾기 위해 역 추적 검색을 수행하는 정렬 알고리즘을 소개합니다. 읽기의 각 문자는 숫자 품질 값을 가지며 값이 낮 으면 시퀀싱 오류가 발생할 가능성이 높음을 나타냅니다. 우리의 맞춤정책의 수를 제한 할 수 있습 불일치 및 선호한 선형가 합의 품질 값이 일치하지 않는 모든 위치가 낮습니다.
검색은 EXACTMATCH 와 유사하게 진행되어 연속적으로 더 긴 쿼리 접미사에 대한 행렬 범위를 계산합니다., 는 경우 이 범위가 빈(접미사에서 발생하지 않는 텍스트),그런 알고리즘을 선택할 수 있습니다 이미 일치하는 쿼리를 위치 및 대체에 다른 기초가 소개하는 불일치로 정렬. EXACTMATCH 검색은 치환된 위치 직후부터 다시 시작됩니다. 알고리즘은 정렬 정책과 일치하고 텍스트에서 한 번 이상 발생하는 수정 된 접미사를 산출하는 이러한 대체 만 선택합니다. 후보 대체 위치가 여러 개인 경우 알고리즘은 최소한의 품질 값을 가진 위치를 탐욕스럽게 선택합니다.,
역추적 시나리오 플레이 밖으로 내에서의 컨텍스트 스택 구조에 자라는 경우 새로운 대체가 소개하고 수축하면 얼라이너를 거부하는 모든 후보자의 선형에 대한 대체재에 스택입니다. 검색이 어떻게 진행될 수 있는지에 대한 그림은 그림 2 를 참조하십시오.
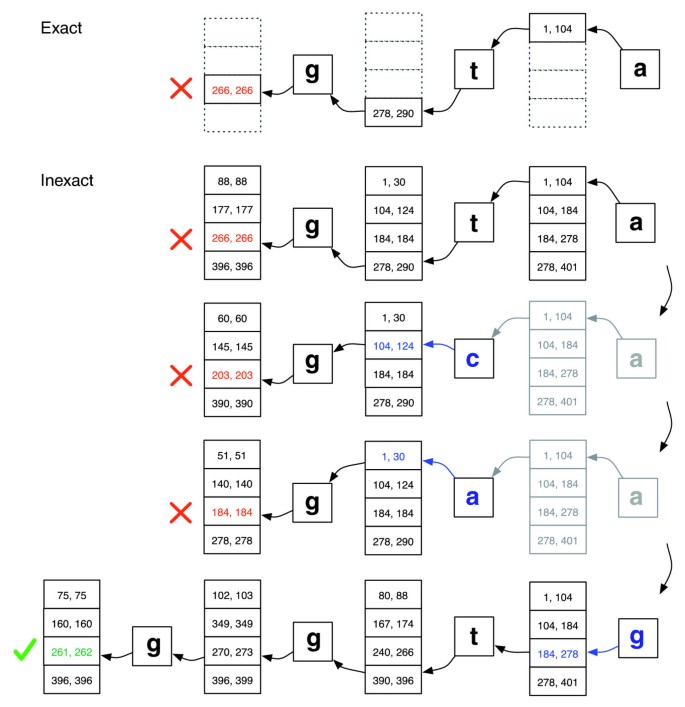
정확하게 일치하는 대 부정확한 정렬., 의 일러스트 방법 EXACTMATCH(최고)하고 넥타의 동기기(바닥)진행이 없을 때 정확하게 일치에 대한 쿼리’ggta’그러나 거기에는 불일치를 정렬할 때’a’대여’g’. 숫자의 박스형 쌍은 해당 지점까지 관찰 된 접미사로 시작하는 행렬 행의 범위를 나타냅니다. 빨간 X 표시는 알고리즘의 만남 빈 범위를 하거나 중단(로 EXACTMATCH)또는 역 추적(에서와 같이 정확하지 않은 알고리즘). Green 확인 표시는 알고리즘을 찾아 비어 있지 않은 범위의 구분을 하나 이상의 항목을 보고성 정렬을 위한 쿼리를 실행합니다.,
에 짧고,넥타이를 실시하고 품질의 인식,greedy,randomized,깊이 첫 번째 검색을 통해 공간의 가능한 선형. 유효한 정렬이 있으면 Bowtie 가이를 찾을 수 있습니다(다음 섹션에서 설명하는 역 추적 천장에 따라 다름). 기 때문에 검색은 욕심,첫 번째 유효한 정렬에 의해 발생하는 넥타이 반드시’최적의’수의 점에서의 또는 불일치의 측면에서 품질입니다., 사용자가를 지시할 수 있 넥타이를 계속 찾을 때까지 그것을 증명할 수 있는 맞춤 보고는’최적의’측면에서의 수는 불일치(옵션을 사용하여–최고). 우리의 경험상,이 모드는 기본 모드보다 2~3 배 느립니다. 대규모 재 시퀀싱 프로젝트에 더 빠른 기본 모드가 선호 될 것으로 기대합니다.
사용자는 또한 선택할 수 있습 넥타이를 보고 모든 선형까지 수를 지정(옵션-k)또는 모든 선형과 수에 제한 없음(옵션)주어진 읽기입니다., 는 경우에는 과정에서의 검색 Bowtie 찾 N 가능한 맞춤 설정의 대체하지만,사용자가 요청만이 선형 K 여기서 K<N,Bowtie 보고합니다 K 의 선형을 선택한다. 이러한 모드는 기본값보다 훨씬 느릴 수 있습니다. 우리의 경험에 비추어 볼 때,예를 들어-k1 은-k2 보다 두 배 이상 빠릅니다.
과도한 역 추적
지금까지 설명한 정렬자는 경우에 따라 과도한 역 추적을 유발하는 시퀀스가 발생할 수 있습니다., 정렬자가 대부분의 노력을 결실없이 쿼리의 3’끝에 가까운 위치로 역 추적 할 때 발생합니다. Bowtie 는’이중 인덱싱’의 새로운 기술로 과도한 역 추적을 완화합니다. 두 개의 인덱스의 게놈이 만들어:중 하나를 포함하는 BWT 의 게놈이라는’앞으로’인덱스이며,두 번째 포함하는 BWT 게놈의의 문자열을 반대하지 않는(반전을 보완)라는’거울을’인덱스입니다. 이것이 어떻게 도움이되는지 확인하려면 정렬에서 하나의 불일치를 허용하는 일치 정책을 고려하십시오., 하나의 불일치가있는 유효한 정렬은 읽기의 어느 절반이 불일치를 포함하는지에 따라 두 가지 경우 중 하나에 해당합니다. Bowtie 는 그 두 가지 경우에 해당하는 두 단계로 진행됩니다. 1 단계는 순방향 인덱스를 메모리에로드하고 쿼리의 오른쪽 절반에있는 위치에서 대체하지 않을 수있는 제약 조건으로 정렬자를 호출합니다. 2 단계 사용하여 미러 인덱스를 호출합 aligner 에 반전 쿼리,제약 조건을 그 얼라이너지를 대체 위치에서 쿼리로 반전의 오른쪽 절반(원래의 쿼리의 왼쪽 절반)., 제약에 역추적으로 오른쪽 절반을 방지하는 과도한 역추적,반면에 사용하는 두 개의 단계와 두 지수를 유지합니다.
불행히도,정렬이 두 개 이상의 불일치를 갖도록 허용 될 때 과도한 역 추적을 완전히 피할 수는 없습니다. 이 실험에서 관찰하는 과도한 역추적이 상당한 경우에만 읽는 많은 낮은 품질의 위치와 맞지 않거나 정렬에 제대로 참조., 이러한 경우 트리거할 수 있는 초과 200 역 추적 읽기당이 있기 때문에 많은 법적인 조합의 낮은 품질의 위치가 탐구하기 전에 모든 가능성 있는 소진된다. 검색이 종료되기 전에 허용되는 역추적 수에 대한 제한을 적용함으로써 이 비용을 완화합니다(기본값:125). 의 제한을 방지 일부 낮은 합법적인 품질을 선형에서 보고되는,그러나 우리가 기대하는 것이 바람직한 무역에 대한 대부분의 응용 프로그램.,
단계적으로 Maq 같은 검색
Bowtie 을 선택 하는 사용자의 수는 불일치를 허용되는(기본값:두)에서 고품질의 끝을 읽을(기본값:28 기초)뿐만 아니라 최대 허용되는 품질이 거리의 전반적인 선형(기본값:70). 품질 값은 것으로 가정에 따라 정의에 PHRED p 는 오류 가능성 및 Q=-10log p.
모두 읽고의 반전을 보완하는 후보에 대한 정렬을 참조합니다. 명확성을 위해이 토론은 앞으로의 방향만을 고려합니다., 역 보완이 어떻게 통합되는지에 대한 설명은 추가 데이터 파일 1(보충 토론 2)을 참조하십시오.
읽기의 고품질 끝에 첫번째 28 의 기초는’씨’에게 불린다. 종자는 두 개의 반쪽으로 구성됩니다:고품질 끝(일반적으로 5’끝)의 14bp 와 저품질 끝의 14bp 는 각각’hi-half’와’lo-half’라고합니다., 고 가정하고 기본사항(두 개의 불일치에서 허용되는 씨앗),보고 맞춤으로 떨어질 것이 하나의 네 가지 경우:없는 불일치에 씨(case1);없는 불일치를 하반기,하나 또는 두 개의 불일치에서 소호-반(case2);없는 불일치에서 소호-상반기,하나 또는 두 개의 불일치에 하반기(케이스 3);및 하나의 불일치에 하반기,하나의 불일치에서 소호-반(경우 4).
모든 경우에 허용하는 어떤 숫자의 불일치에 nonseed 의 한 부분을 읽고 모든 경우에도 적용하여 품질의 거리 제한이었습니다.,
Bowtie 알고리즘으로 구성의 세 가지 단계는 다른 사용하는 사이에 앞으로 그리고 거울 지수,도 3 에 도시 된 바와 같이. 1 단계는 미러 인덱스를 사용하고 정렬자를 호출하여 사례 1 과 2 에 대한 정렬을 찾습니다. 2 단계 및 3 단계 협력을 찾을 선형에 대한 사례 3:2 단계 부분을 발견 선형과 불일치만에 하이-반고 3 단계 시장 그 부분적인 선형으로 제공됩니다. 마지막으로 3 단계는 정렬자를 호출하여 사례 4 에 대한 정렬을 찾습니다.,

세계의 Bowtie 알고리즘에 대한 Maq 같은 정책이 있습니다. 3 상 접근법은 역 추적을 최소화하면서 2 개의 불일치 사례 1~4 에 대한 정렬을 찾습니다. 1 단계는 미러 인덱스를 사용하고 정렬자를 호출하여 사례 1 과 2 에 대한 정렬을 찾습니다. 2 단계 및 3 단계 협력을 찾을 선형에 대한 사례 3:2 단계 부분을 발견 선형과 불일치만에 하이-반고 3 단계 시장 그 부분적인 선형으로 제공됩니다., 마지막으로 3 단계는 정렬자를 호출하여 사례 4 에 대한 정렬을 찾습니다.
성능 결과
우리는 우리의 성능을 평가 넥타이를 사용하여 읽어에서 1,000 개의 게놈 프로젝트 파일럿(National Center for 생명공학 정보보보 아카이브:SRR001115). Illumina 계측기의 데이터 1 차선에 대해 총 8,84 만 건의 읽기가 35bp 로 트리밍되어 인간 참조 게놈에 정렬되었습니다. 달리 지정하지 않는 한,읽기 데이터는 아카이브에 표시되는 방식에서 필터링되거나 수정되지 않습니다(트리밍 외에)., 이것은 게놈에 어딘가에 정렬 읽기의 약 70%~75%로 이어집니다. 우리의 경험에 비추어 볼 때 이것은 아카이브의 원시 데이터에 일반적입니다. 보다 적극적인 필터링은 더 높은 정렬 속도와 더 빠른 정렬을 유도합니다.
모든 실행은 단일 CPU 에서 수행되었습니다. Bowtie 스피드 업은 벽시계 정렬 시간의 비율로 계산되었습니다. 입력/출력 부하와 CPU 경합이 중요한 요소가 아님을 보여주기 위해 벽시계와 CPU 시간이 모두 제공됩니다.
Bowtie 지수를 구축하는 데 필요한 시간은 Bowtie 실행 시간에 포함되지 않았습니다., 경쟁 도구와 달리 Bowtie 는 많은 정렬 실행에서 참조 게놈에 대해 사전 계산 된 인덱스를 재사용 할 수 있습니다. 우리는 대부분의 사용자가 단순히 공개 저장소에서 그러한 색인을 다운로드 할 것으로 예상합니다. Bowtie 사이트는 인간,침팬지,마우스,개,쥐 및 Arabidopsis thaliana genomes 의 현재 빌드뿐만 아니라 많은 다른 것들에 대한 지수를 제공합니다.
결과를 얻었다에 두 개의 하드웨어 플랫폼:탁상용 워크스테이션 2.4GHz Intel Core2 개 프로세서와 2gb RAM;그리고 대형 메모리 서버와 함께 네 개의 코어 2.4GHz AMD Opteron 프로세서와 32GB RAM., 이들은 각각’PC’와’서버’로 표시됩니다. PC 와 서버 모두 red Hat Enterprise Linux 를 릴리스 4 로 실행합니다.
비하면 비누와 Maq
Maq 인기 있는 얼라이너는 가장 빠르게 경쟁하는 오픈 소스 도구를 맞추기 위해 수백만 개의 Illumina 읽는 인간 게놈. SOAP 은 짧은 읽기 프로젝트에서보고되고 사용 된 또 다른 오픈 소스 도구입니다.
표 1 은 Bowtie v0.9.6,SOAP v1.10 및 Maq v0.6.6 의 성능과 감도를 제시합니다. SOAP 의 메모리 풋 프린트가 PC 의 실제 메모리를 초과하므로 PC 에서 SOAP 을 실행할 수 없습니다. ‘비누.,contig’버전의 SOAP 바이너리가 사용되었습니다. 비교를 위해 비누,넥타이 호출되었으로’-v2’을 모방 비누의 기본 일치하는 정책(수 있는 최대 두 개의 불일치에 정렬을 무시하고 품질의 값)와 함께’–maxns5’시뮬레이션 비누의 기본 정책을의 필터링을 읽으로 다섯 개 또는 더없이 신뢰를 기지. 에 대한 Maq 비교 Bowtie 실행의 기본 정책을 모방 Maq 의 기본 정책을 허용하는 최대 두 개의 불일치에서 첫 번째 28 지하고 적용하는 전체적 제한의 70 에 합의 품질 값이 일치하지 않는 모든 읽는 위치입니다., Bowtie 의 메모리 풋 프린트를 Maq 와 더 비슷하게 만들기 위해 bowtie 는 모든 실험에서’-z’옵션으로 호출되어 한 번에 forward 또는 mirror index 만 메모리에 상주하도록합니다.
정렬 된 읽기 수는 SOAP(67.3%)와 Bowtie-v2(67.4%)가 비교 감도를 가지고 있음을 나타냅니다. 의 읽기 정렬하여 비누 또는 Bowtie,99.7%었으로 정렬 모두 0.2%었으로 정렬되어 Bowtie 하지만 비누,0.1%었으로 정렬되어 비누지 Bowtie. Maq(74.7%)와 Bowtie(71.9%)도 Bowtie 가 2.8%지연되지만 대략 비교 가능한 감도를 가지고 있습니다., 의를 읽으로 정렬되어 중 Maq 또는 Bowtie,96.0%었으로 정렬 모두 0.1%었으로 정렬되어 Bowtie 지 Maq,3.9%었으로 정렬되어 Maq 지 Bowtie. 의 읽기 매핑 Maq 지 Bowtie,거의 모든 때문에 유연성을 Maq 의 선형 알고리즘을 할 수있는 몇 가지 정렬은 세 가지 불일치에서 씨앗이다. Maq 에 의해 매핑되었지만 Bowtie 가 아닌 읽기의 나머지 부분은 Bowtie 의 역 추적 천장 때문입니다.
Maq 의 문서에는’poly-a 아티팩트’가 포함 된 읽기가 Maq 의 성능을 손상시킬 수 있다고 언급되어 있습니다., 표 2 는 폴리-a 아티팩트를 제거하기 위해 maq 의’catfilter’명령을 사용하여 읽기 세트가 필터링 될 때 Bowtie 및 Maq 의 성능 및 민감도를 제시합니다. 필터는 8,839,010 읽기 중 438,145 를 제거합니다. 다른 실험 매개 변수는 표 1 의 실험과 동일하며 Bowtie 와 Maq 의 상대적 민감도에 대한 동일한 관찰이 여기에 적용됩니다.
읽는 길이고 성능
으로 시퀀싱 기술을 향상시킵 읽고,길이가 성장을 넘어 30bp50bp 일반적으로 볼 수 있는 공용 데이터베이스에서 오늘입니다., Bowtie,Maq 및 SOAP 는 각각 최대 1,024,63 및 60bp 길이의 읽기를 지원하며 Maq 버전 0.7.0 이상은 최대 127bp 의 읽기 길이를 지원합니다. 표 3 성능을 때의 결과는 세 가지 도구가 있는 각 정렬하는 데 사용되는 세 가지의 2M 림 읽기,36bp 설정,50bp 정 및 76bp 설정하는 인간 게놈 서버에 있는 플랫폼입니다. 2m 의 각 세트는 더 큰 세트(ncbi Short Read Archive:36-bp 의 경우 SRR003084,50-bp 의 경우 SRR003092,76-bp 의 경우 srr003196)에서 무작위로 샘플링됩니다., 읽기는 2m 의 3 세트가 per-base Phred 자질으로부터 계산 된 바와 같이 균일 한 per-base 오류율을 갖도록 샘플링되었다. 모든 읽기는 Maq 의’catfilter’를 통과합니다.
넥타이 모두 실행에 Maq 같은 기본 모드에서의 비누 같은’-v2’모드입니다. Bowtie 는 또한 한 번에 forward 또는 mirror index 만 메모리에 상주하도록하는’-z’옵션이 제공됩니다. Maq v0.7.1 은 v0.6 때문에 76-bp 세트에 대해 Maq v0.6.6 대신 사용되었습니다.,6 63bp 보다 긴 읽기를 정렬할 수 없습니다. SOAP 는 60bp 보다 긴 읽기를 지원하지 않기 때문에 76-bp 세트에서 실행되지 않았습니다.
결과는 Maq 의 알고리즘이 Bowtie 또는 SOAP 보다 긴 읽기 길이로 전반적으로 더 잘 확장된다는 것을 보여줍니다. 그러나 비누와 같은’-v2’모드의 Bowtie 도 매우 잘 확장됩니다. 기본 Maq 와 같은 모드의 Bowtie 는 36-bp 에서 50-bp 읽기로 잘 확장되지만 여전히 Maq 보다 빠른 크기의 순서 이상이지만 76-bp 읽기에는 실질적으로 느립니다.,
병렬 성능
정렬할 수 있습 병렬화된 배포하여 읽기를 통해 동시에 검색 스레드입니다. Bowtie 는 사용자가 원하는 스레드 수(옵션-p)를 지정할 수있게하며 Bowtie 는 pthreads 라이브러리를 사용하여 지정된 스레드 수를 시작합니다. 넥타이 스레드 동기화를 서로를 가져오는 경우를 읽고,출력 결과를 사이에서 전환하는 지표이며,이를 수행하는 다양한 형태의 글로벌 부과 같은 표시 읽음으로’수행’., 그렇지 않으면 스레드가 병렬로 자유롭게 작동하여 여러 프로세서 코어가있는 컴퓨터에서 정렬을 실질적으로 가속화합니다. 인덱스의 메모리 이미지는 모든 스레드에서 공유되므로 여러 스레드가 사용될 때 풋 프린트가 실질적으로 증가하지 않습니다. 표 4 는 4 코어 서버에서 Bowtie v0.9.6 을 1 개,2 개 및 4 개의 스레드로 실행한 성능 결과를 보여줍니다.,
인덱스 구축
넥타이를 사용한 인덱싱 알고리즘을 구성할 수 있는 무역 사 메모리 사용량과 실행하는 시간입니다. 표 5 는 전체 인간 참조 게놈(NCBI build36.3,contigs)을 인덱싱 할 때이 트레이드 오프를 보여줍니다. 실행은 서버 플랫폼에서 수행되었습니다. 인덱서는 메모리 사용량에 대한 상한선이 다른 4 번 실행되었습니다.,
보고 시간과 비교해도 손색 맞춤간의 경쟁 도구들을 수행하는 인덱싱 동안 정렬. 보다 적은 5 시간이 필요한 넥타이를 모두 구축하고 쿼리 전체적 인간 인덱스 8.84 백만에서 읽고 1,000 개의 게놈 프로젝트(NCBI 보보 아카이브:SRR001115)서버에 보다 더 급 이상 빠른 해당하는 Maq 실행됩니다., 아래는 가장 행함을 보여 줍니다 Bowtie 인덱서 적합한 인수,메모리 효율적인을 실행하기에 충분한 일반적인 워크스테이션 2GB RAM. 추가 데이터 파일 1(보충 토론 3 및 4)은 알고리즘과 결과 인덱스의 내용을 설명합니다.
소프트웨어
Bowtie 는 C++로 작성되었으며 SeqAn 라이브러리를 사용합니다. Maq 매핑 형식의 변환기는 Maq 의 코드를 사용합니다.피>