Bowtieは、Burrows-Wheeler transform(BWT)とFM indexに基づくスキームを用いて参照ゲノムをインデックス化します。 ヒトゲノムのBowtieインデックスはディスク上の2.2GBに収まり、アライメント時にわずか1.3GBのメモリフットプリントを持ち、2GB未満のRAMを持つワークステーションで照会できるようになっている。,
FMインデックスで検索するための一般的な方法は、FerraginaとManziniの完全一致アルゴリズムです。 厳密な一致はシーケンシングエラーや遺伝的変異を可能にしないため、Bowtieは単にこのアルゴリズムを採用し この技術を短い読み取りアライメントに適用できるようにする二つの新しい拡張を紹介した。, Bowtie alignerは、各読み取りの高品質の終わり内で少数の不一致を可能にし、不一致の整列位置での品質値の合計に上限を設けるという点で、Maqと同様のポリシーに従っています。
Burrows-Wheeler indexing
BWTは、テキスト内の文字の可逆的な順列です。 が独自開発のコンテキスト内のデータ圧縮、BWTに基づく割り出することができ、大型テキスト検索対象となる効率的な小型メモリフットプリント, これは、オリゴマーカウント、全ゲノムアライメント、タイリングマイクロアレイプローブ設計、およびヒトサイズの参照にスミスウォーターマンアライメント
テキストTのBurrows-Wheeler変換BWT(T)は、次のように構成されます。 ここで、$はTにはなく、辞書的にTのすべての文字よりも小さくなります。TのBurrows-Wheeler行列は、行がT$のすべての循環回転を含む行列として構成されます。 その後、行は辞書順にソートされます。, BWT(T)は、Burrows-Wheeler行列の右端の列にある文字のシーケンスです(図1a)。 BWT(T)の長さは元のテキストTと同じです。
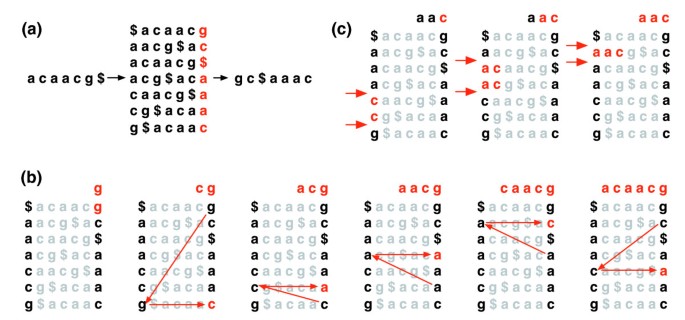
バローズ-ウィーラー変換。 (a)’acaacg’に対するBurrows-Wheeler行列と変換。 (b)行の範囲を識別するためにEXACTMATCHによって実行されるステップ、したがって’aac’の接頭辞が付いた参照接尾辞のセット。, (c)UNPERMUTEは、Burrows-Wheeler変換(右端の列で黒)から元のテキスト(一番上の行の赤)を復元するために、最後の最初の(LF)マッピングを繰り返し適用します。
この行列には、”最後の最初(LF)マッピング”と呼ばれるプロパティがあります。 最後の列の文字Xのi番目の出現は、最初の列のxのi番目の出現と同じテキスト文字に対応します。 このプロパティは、BWTインデックスを使用してテキ, 図1bは、BWT(T)からTを再作成するためにLFマッピングを繰り返し適用するアルゴリズムであるUNPERMUTEを示しています。
LFマッピングは完全マッチングにも使用されます。 行列は辞書順に並べ替えられるため、指定されたシーケンスで始まる行は連続して表示されます。 一連のステップで、EXACTMATCHアルゴリズム(図1c)は、クエリの連続した長いサフィックスで始まる行列行の範囲を計算します。 各ステップで、範囲のサイズは縮小するか、または同じままになります。, アルゴリズムが完了すると、S0(クエリ全体)で始まる行は、テキスト内のクエリの正確な出現に対応します。 範囲が空の場合、テキストにはクエリが含まれません。 アンペルミュートはバローズとウィーラーに、フェラギーナとマンジーニにそれぞれ影響を与えている。 詳細は、追加データファイル1(補足説明1)を参照してください。
不正確な整列の検索
整列に不一致が含まれている可能性があるため、EXACTMATCHは短い読み取り整列には不十分です。, を紹介し、アライメントアルゴリズムを行う消検索をアライメントが満足する指定された配列。 読み取りの各文字には数値の品質値があり、値が小さいほどシーケンスエラーの可能性が高いことを示します。 当社のアライメントポリシーでは、ミスマッチの数が限られており、すべてのミスマッチポジションでの品質値の合計が低いアライメントを好みます。
検索はEXACTMATCHと同様に進行し、連続して長いクエリサフィックスの行列範囲を計算します。, 範囲が空になった場合(テキストに接尾辞がない場合)、アルゴリズムはすでに一致したクエリ位置を選択し、そこで異なるベースを置き換えることができ、アライメントに不一致が生じることがあります。 EXACTMATCH検索は、置換された位置の直後から再開されます。 このアルゴリズムは、配置ポリシーと一致し、テキスト内で少なくとも一度は発生する変更されたサフィックスを生成する置換のみを選択します。 複数の候補置換位置がある場合、アルゴリズムは、最小の品質値を持つ位置を貪欲に選択します。,
バックトラッキングシナリオは、新しい置換が導入されたときに成長し、アライナが現在スタック上にある置換のすべての候補整列を拒否すると 検索がどのように進むかの図については、図2を参照してください。
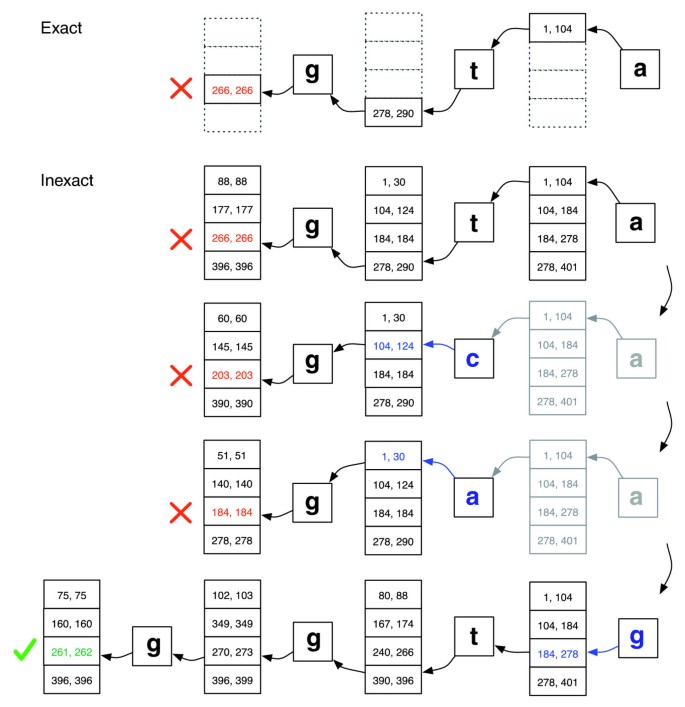
正確なマッチングと不正確なアライメント。, クエリ’ggta’に完全一致がないが、’a’が’g’に置き換えられたときに一つの不一致の配置がある場合、EXACTMATCH(上)とBowtieのaligner(下)がどのように進行するかの図。 ボックス化された数値のペアは、その時点までに観測された接尾辞で始まる行列の行の範囲を示します。 赤いXは、アルゴリズムが空の範囲に遭遇し、アボート(EXACTMATCHのように)またはバックトラック(inexactアルゴリズムのように)のいずれかを示します。 緑色のチェックマークは、アルゴリズムがクエリのレポート可能な配置の一つ以上の出現を区切る空でない範囲を見つけることを示します。,
要するに、Bowtieは、可能な整列の空間を通して、品質を認識し、貪欲で、無作為化され、深さ優先の検索を行います。 有効なアライメントが存在する場合、Bowtieはそれを見つけます(次のセクションで説明するバックトラック天井に従います)。 検索は貪欲であるため、Bowtieが遭遇する最初の有効なアライメントは、不一致の数または品質の点で必ずしも”最良”ではありません。, ユーザーは、Bowtieが報告する整列が不一致の数に関して”最良”であることを証明できるまで(オプション–bestを使用して)検索を継続するように指示すること 私たちの経験では、このモードは、デフォルトのモードよりも二から三倍遅いです。 しかし、実際にやってみると高速のデフォルトモードにすることを目標と大きな再配列。
ユーザーは、Bowtieを選択して、指定された数までのすべての整列(オプション-k)または指定された読み取りの数に制限のないすべての整列(オプション-a)を, 検索の過程でBowtieが特定の置換セットに対してN個の可能な整列を見つけたが、ユーザーがk<Nのk整列のみを要求した場合、Bowtieはランダムに選択されたN個の整列のKを報告します。 これらのモ 私たちの経験では、例えば、-k1は-k2の倍以上の速さです。
過度のバックトラッキング
これまでに説明したアライナは、場合によっては、過度のバックトラッキングを引き起こすシーケンスに遭遇する, これは、アライナがクエリの3’終わりに近い位置に無駄にバックトラッキングするほとんどの労力を費やしている場合に発生します。 ボウタイは、”ダブルインデックス”の新しい技術で過度のバックトラックを軽減します。 ゲノムの二つのインデックスが作成されます:ゲノムのBWTを含むものは”フォワード”インデックスと呼ばれ、ゲノムのBWTを含むもう一つは”ミラー”インデックスと呼ばれる文字配列を逆にした(逆補完されていない)。 これがどのように役立つかを確認するには、整列の不一致を許可する一致ポリシーを検討します。, 一つの不一致を持つ有効なアライメントは、読み取りの半分が不一致を含む二つのケースのいずれかに分類されます。 ボウタイはこれら二つのケースに対応する二つの段階で進行する。 フェーズ1は、前方インデックスをメモリにロードし、クエリの右半分の位置で置換できない制約を持つアライナを呼び出します。 フェーズ2では、ミラーインデックスを使用して、逆のクエリでアライナを呼び出しますが、逆のクエリの右半分(元のクエリの左半分)の位置でアライナを置き換えることができないという制約があります。, 右半分へのバックトラッキングの制約は、過度のバックトラッキングを防ぎますが、二つのフェーズと二つのインデックスの使用は完全な感度を維持
残念ながら、整列が複数の不一致を持つことが許可されている場合、過度のバックトラッキングを完全に回避することはできません。 私たちの実験では、過度のバックトラッキングは、読み取りが多くの低品質の位置を持ち、参照に整列または整列しない場合にのみ重要であること, すべての可能性が使い果たされる前に検討される低品質の位置の多くの法的な組み合わせがあるので、これらのケースは、読み取りあたり200バックト 検索が終了するまでに許可されるバックトラックの数に制限を適用することにより、このコストを軽減します(デフォルト:125)。 この制限により、いくつかの正当な低品質の整列が報告されることを防ぎますが、これはほとんどのアプリケーションにとって望ましいトレードオフ,
フェーズドMaqのような検索
Bowtieは、ユーザーが読み取りの高品質の終わり(デフォルト:最初の28塩基)だけでなく、全体的なアライメントの最大許容品質距離(デフォルト:70) 品質値はPHREDの定義に従うと仮定され、ここで、pは誤りの確率であり、Q=-10log pである。
読み取りとその逆補数の両方が参照へのアライメントの候補である。
明確にするために、この議論では、前方の方向のみを考慮します。, 他のデータファイル1(補助ディスカッション2)についての説明がどのようにreverse complementが内蔵されています。
読み取りの高品質の終わりに最初の28塩基は、”シード”と呼ばれています。 シードは二つの半分で構成されています:高品質の端(通常は5’端)の14bpと低品質の端の14bpは、それぞれ”こんにちは半分”と”lo半分”と呼ばれます。, こんにちはこんにちはこんにちはこんにちはこんにちはこんにちはこんにちはこんにちはこんにちはこんにちはこんにちはこんにちはこんにち
すべてのケースでは、読み取りの非シード部分で任意の数の不一致が許可され、すべてのケースも品質距離制約の対象となります。,
蝶アルゴリズムの位相が交互利用のミラー指数、図3のような フェーズ1のミラー指数を呼び出し、アライナーを探ペ例1および2. こんにちは、フェーズ2と3は、ケース3の整列を見つけるために協力します:フェーズ2は、hi-halfでのみ不一致を持つ部分整列を検出し、フェーズ3は、これらの部分整列を完全整列に拡張しようとします。 最後に、フェーズ3はアライナを呼び出してケース4のアライメントを見つけます。,

Maqのようなポリシーのためのボウタイアルゴリズムの三つのフェーズ。 三相アプローチでは、バックトラッキングを最小限に抑えながら、二つの不一致ケース1から4の整列を検出します。 フェーズ1のミラー指数を呼び出し、アライナーを探ペ例1および2. こんにちは、フェーズ2と3は、ケース3の整列を見つけるために協力します:フェーズ2は、ハイハーフでのみ不一致を持つ部分整列を見つけ、フェーズ3は、これらの部分整列を完全整列に拡張しようとします。, 最後に、フェーズ3はアライナを呼び出してケース4のアライメントを見つけます。
パフォーマンス結果
1,000ゲノムプロジェクトパイロット(国立バイオテクノロジー情報センター短い読み取りアーカイブ:SRR001115)からの読み取りを使用してボウタイ イルミナ機器からのデータの約8.84万読み取りの合計は、35bpにトリミングされ、ヒト参照ゲノムに整列しました。 特に指定がない限り、読み出しデータなフィルタまたは変更(以外のトリミング)からどのように表示されるアーカイブを展開します。, これにより、読み取りの約70%から75%がゲノムのどこかに整列しています。 私たちの経験では、これはアーカイブからの生データの典型的なものです。 より積極的なろ過はより高い直線率およびより速い直線をもたらす。
すべての実行は単一のCPU上で実行されました。 ボウタイスピードアップは、壁時計のアライメント時間の比として計算されました。 ウォールクロックとCPU時間の両方を与えて、入出力負荷とCPU競合が重要な要因ではないことを示します。
Bowtie indexを作成するのに必要な時間はBowtie実行時間に含まれていませんでした。, とは異なり競争具、蝶再利用することも可能で計算した指数の参照ゲノム全体を多く配置です。 ほとんどのユーザーは、公開リポジトリからそのようなインデックスを Bowtieサイトは、ヒト、チンパンジー、マウス、イヌ、ラット、およびシロイヌナズナのゲノムだけでなく、他の多くの現在のビルドのための指標を提供します。2.4GHz Intel Core2プロセッサと2GBのRAMを搭載したデスクトップワークステーションと、2.4GHz AMD Opteronプロセッサと32GBのRAMを搭載した大容量メモリサーバーである。, これらはそれぞれ’PC’および’server’と表されます。 PCとサーバーの両方がred Hat Enterprise Linuxをリリース4として実行します。
SOAPおよびMaqとの比較
Maqは、数百万のIllumina読み取りをヒトゲノムに整列させるための最も速い競合するオープンソースツールの一つである人気のあるアライナです。 ソープもオープンソースのツールと報告されて使用され、短読み込みます。
表1に、Bowtie v0.9.6、SOAP v1.10、およびMaq v0.6.6のパフォーマンスと感度を示します。 SOAPのメモリフットプリントがPCの物理メモリを超えているため、PC上でSOAPを実行できませんでした。 “ソープ”,contig’バージョンのSOAPバイナリが使用されました。 SOAPとの比較のために、BowtieはSOAPのデフォルトの一致ポリシーを模倣するために’-v2’で呼び出され、’–maxns5’で呼び出され、SOAPのデフォルトの読み取りをフィルタリングするポリシーをシミュレートしました。 Maqの比較では、Bowtieは最初の28塩基で最大二つの不一致を許可し、すべての不一致の読み取り位置で品質値の合計に70の全体的な制限を適用するMaqのデフォルトポリシーを模倣したデフォルトポリシーで実行されます。, BowtieのメモリフットプリントをMaqと比較するために、Bowtieはすべての実験で’-z’オプションで呼び出され、フォワードまたはミラーインデックスのみが一度にメモリに常駐するようになります。
整列された読み取り数は、SOAP(67.3%)およびBowtie-v2(67.4%)が同等の感度を有することを示す。 石鹸またはボウタイのいずれかによって整列された読み取りのうち、99.7%は両方によって整列され、0.2%はボウタイで整列されたが、石鹸では整列され、0.1%は石鹸で整列されたがボウタイでは整列されなかった。 Maq(74.7%)とBowtie(71.9%)もほぼ同等の感度を持っていますが、Bowtieは2.8%遅れています。, Maqまたはボウタイのいずれかによって整列された読み取りのうち、96.0%は両方によって整列され、0.1%はボウタイで整列されたが、Maqではなく、3.9%はMaqによって整列されたが、ボウタイでは整列されなかった。 Maqによってマッピングされた読み取りのうち、BowtieではなくMaqによってマッピングされた読み取りのほとんどは、Maqのアライメントアルゴリズムの柔軟性によるものです。 Maqによってマッピングされた読み取りの残りの部分は、Bowtieのバックトラッキング天井によるものです。
Maqの文書では、’poly-A artifacts’を含む読み取りはMaqのパフォーマンスを損なう可能性があると述べています。, 表2に示性能と感度と蝶Maq場合、読み込みに設定するフィルタを用いMaqのcatfilter’コマンドをポリAの遺 このフィルタは、438,145の読み取りのうち8,839,010を排除します。 その他の実験パラメータは表1の実験と同じであり、BowtieとMaqの相対感度に関する同じ観測がここで適用されます。
読み取りの長さとパフォーマンス
シーケンシング技術が向上するにつれて、読み取りの長さは、今日の公共データベースで一般的に見られる30bpから50bp, Bowtie、Maq、SOAPは、それぞれ最大1,024bp、63bp、および60bpの読み取りをサポートし、Maqバージョン0.7.0以降では最大127bpの読み取り長さをサポートします。 表3に、2つのツールを使用して、サーバープラットフォーム上のヒトゲノムに、36bpセット、50bpセット、76bpセットの三つのセットを整列させた場合のパフォーマン 2つのMの各セットは、より大きなセットからランダムにサンプリングされます(NCBI短い読み取りアーカイブ:SRR003084は36-bp、SRR003092は50-bp、SRR003196は76-bp)。, 読み取りは、2Mの三組が塩基当たりのPhred品質から計算されるように、均一な塩基当たりの誤り率を有するようにサンプリングされた。 すべての読み取りはMaqの’catfilter’を通過します。
Bowtieは、MaqのようなデフォルトモードとSOAPのような’-v2’モードの両方で実行されます。 Bowtieには、前方またはミラーインデックスのみが一度にメモリに常駐するようにするための’-z’オプションも与えられます。 Maq v0.7.1はmaq v0.6.6の代わりに使用され、76-bpセットはv0.6であるためです。,6 63bpより長い読み取りを整列できません。 SOAPは76bpセットでは60bpより長い読み取りをサポートしていないため、実行されませんでした。
結果は、MaqのアルゴリズムがBowtieやSOAPよりも全体的に長い読み取り長にスケーリングされることを示しています。 しかし、石鹸のような’-v2’モードのボウタイも非常によくスケールします。 デフォルトのMaqのようなモードのBowtieは36bpから50bpの読み取りによくスケーリングされますが、76bpの読み取りでは大幅に遅くなりますが、Maqよりも一桁,
並列パフォーマンス
アライメントは、同時検索スレッド間で読み取りを分散することによって並列化できます。 Bowtieは、ユーザーが希望する数のスレッドを指定できます(オプション-p)。Bowtieは、pthreadsライブラリを使用して指定した数のスレッドを起動します。 ボウタイスレッドは、読み取りのフェッチ、結果の出力、インデックス間の切り替え、および読み取りを”完了”としてマークするなど、さまざまな形式のグローバ, 他のスレッドに並行して稼働を大幅に加速アライメントコンピュータに複数のプロセッサコアを用いた のメモリイメージのインデックスを指定で共有すべてのスレッドなどのフットプリントしない大幅な増加が複数のスレッドを使用します。 表4に、Bowtie v0.9.6を一つ、二つ、四つのスレッドを持つ四つのコアサーバーで実行した場合のパフォーマンス結果を示します。,
Index building
Bowtieは、メモリ使用量と実行時間の間でトレードオフするように構成できる柔軟なインデックス 表5は、ヒト参照ゲノム全体を索引付けするときのこのトレードオフを示しています(NCBI build36.3、contigs)。 走行には、サーバます。 インデクサーは、メモリ使用量の上限が異なる四回実行されました。,
報告された時間は、アライメント中にインデックスを実行する競合ツールのアライメント Bowtieがサーバー上の8.84ゲノムプロジェクト(NCBI Short Read Archive:SRR001115)から1,000万の読み取りを行い、ヒト全体のインデックスを構築してクエリするのに5時間未満が必要であり、同等のMaq実行よりも六倍速くなっている。, 一番下の行は、適切な引数を持つBowtieインデクサーが、2GBのRAMを備えた一般的なワークステーションで実行するのに十分なメモリ効率であることを示して 追加データファイル1(補足議論3および4)は、アルゴリズムと結果の索引の内容を説明します。
ソフトウェア
BowtieはC++で書かれており、SeqAnライブラリを使用しています。 Maqマッピング形式へのコンバーターは、Maqのコードを使用します。