Bowtie a referencia genomot a Burrows-Wheeler transzformáción (BWT) és az FM Indexen alapuló séma alapján indexeli . Az emberi genomhoz tartozó Bowtie-index 2,2 GB-os lemezre illeszkedik, és a memória lábnyoma alig 1,3 GB-os az összehangolási időben, lehetővé téve a lekérdezést egy 2 GB RAM alatti munkaállomáson.,
az FM indexben történő keresés közös módszere a Ferragina és a Manzini pontos egyező algoritmusa . Bowtie nem egyszerűen elfogadja ezt az algoritmust, mert a pontos illesztés nem teszi lehetővé a szekvenálási hibákat vagy genetikai variációkat. Bemutatjuk a két regény fájlokat, amelyek a technika alkalmazható rövid olvassa el igazítás: minőségi tudja bemagyarázni algoritmus, amely lehetővé teszi, eltérések kedveli a magas minőségű nyomvonalakat; valamint dupla indexelés’, egy stratégia, hogy elkerüljék a túlzott sehová., A Bowtie aligner a Maq-hoz hasonló politikát követ, mivel lehetővé teszi, hogy az egyes olvasmányok kiváló minőségű végén kis számú eltérés legyen, és a minőségi értékek összegére felső korlátot helyez el a nem megfelelő igazítási pozíciókban.
Burrows-Wheeler indexelés
a BWT a szövegben szereplő karakterek reverzibilis permutációja. Bár eredetileg az adattömörítés keretében fejlesztették ki, a BWT-alapú indexelés lehetővé teszi a nagy szövegek hatékony keresését egy kis memória lábnyomban., Ez alkalmazták a bioinformatikát alkalmazások, beleértve oligomer számítva , az egész genom igazítás , csempézés microarray szonda design , Smith-Waterman igazítás, hogy egy emberi méretű referencia .
A T, BWT(T) szöveg Burrows-Wheeler transzformációja a következőképpen épül fel. A $ karakter T-hez van csatolva, ahol a $ Nincs T-ben, és lexikográfiailag kevesebb, mint a T összes karaktere.a T Burrows-Wheeler mátrixa mátrixként van kialakítva, amelynek sorai a t$összes ciklikus forgását tartalmazzák. A sorokat ezután lexikográfiailag rendezik., A BWT (T) a Burrows-Wheeler mátrix jobb szélső oszlopában lévő karakterek sorozata (1a ábra). A BWT (T) hossza megegyezik az eredeti T.
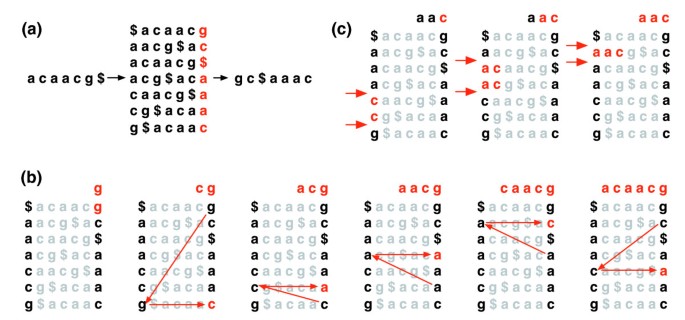
Burrows-Wheeler transform. a) A Burrows-Wheeler mátrix és az “acaacg” transzformációja. b) az EXACTMATCH által tett lépések a sorok tartományának, így az ” aac ” által előtagolt referencia utótagok halmazának azonosítására., (c) UNPERMUTE ismételten alkalmazza az utolsó első (LF) leképezés, hogy visszaszerezze az eredeti szöveget (piros a felső sorban) a Burrows-Wheeler transform (fekete A jobb szélső oszlopban).
Ez a mátrix az “utolsó első (LF) leképezés” nevű tulajdonsággal rendelkezik. Az utolsó oszlopban az X karakter i-edik előfordulása megegyezik az első oszlopban az X i-edik előfordulásával. Ez a tulajdonság olyan algoritmusok alapját képezi, amelyek a BWT indexet használják a szöveg navigálásához vagy kereséséhez., 1b ábra szemlélteti UNPERMUTE, egy algoritmus, amely alkalmazza az LF leképezés többször újra létrehozni T BWT (T).
az LF leképezést a pontos illesztéshez is használják. Mivel a mátrix lexikográfiailag van rendezve, az adott szekvenciával kezdődő sorok egymás után jelennek meg. Egy sor lépésben az EXACTMATCH algoritmus (1C ábra) kiszámítja a mátrix sorok tartományát, amelyek a lekérdezés egymást követő hosszabb utótagjaival kezdődnek. Minden lépésben a tartomány mérete vagy csökken, vagy ugyanaz marad., Amikor az algoritmus befejeződik, az S0-val kezdődő sorok (a teljes lekérdezés) megfelelnek a lekérdezés pontos előfordulásának a szövegben. Ha a tartomány üres, a szöveg nem tartalmazza a lekérdezést. Az UNPERMUTE-ot Burrows-nak és Wheelernek, valamint FERRAGINÁNAK és Manzininek tulajdonítják . A részletekért lásd az 1.kiegészítő adatfájlt (kiegészítő Vita 1).
Keres pontatlan nyomvonalakat
EXACTMATCH nem elegendő a rövid olvassa el igazítás, mert nyomvonalakat tartalmazhatnak eltéréseket, ami miatt lehet, hogy sorrendi hibák, valódi különbség a referencia-vizsgálat szervezetekre, vagy mindkettő., Bemutatunk egy igazítási algoritmust, amely nyomon követési keresést végez, hogy gyorsan megtalálja a megadott igazítási házirendet kielégítő igazításokat. Az olvasás minden karakterének numerikus minőségi értéke van, alacsonyabb értékek jelzik a szekvenálási hiba nagyobb valószínűségét. Igazítási politikánk korlátozott számú eltérést tesz lehetővé, és előnyben részesíti az igazításokat, ahol a minőségi értékek összege minden nem megfelelő pozícióban alacsony.
a keresés az EXACTMATCH-hez hasonlóan folytatódik, kiszámítva a mátrix tartományokat egymás után hosszabb lekérdezési utótagokhoz., Ha a tartomány üres lesz (a szövegben nem fordul elő utótag), akkor az algoritmus kiválaszthat egy már egyeztetett lekérdezési pozíciót, és helyettesíthet egy másik bázist, ami eltérést vezet be az igazításba. Az EXACTMATCH keresés közvetlenül a helyettesített pozíció után folytatódik. Az algoritmus csak azokat a szubsztitúciókat választja ki, amelyek összhangban vannak az igazítási politikával, és amelyek a szövegben legalább egyszer előforduló módosított utótagot eredményeznek. Ha több jelölt helyettesítési pozíció van, akkor az algoritmus mohón kiválaszt egy minimális minőségi értékű pozíciót.,
Visszalépés forgatókönyvek ki a játék keretein belül egy stack felépítése, hogy a nő, amikor egy új helyettesítő be, pedig zsugorodik, amikor az igazító elutasítja a jelölt nyomvonalakat a cserék jelenleg a verem. Lásd a 2. ábrát a keresés folytatásának szemléltetéséhez.
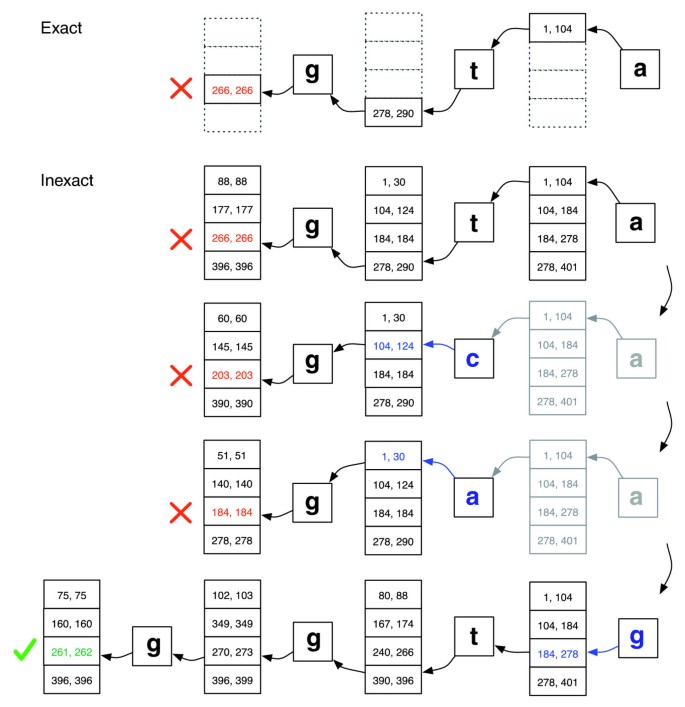
pontos illesztés a pontatlan igazításhoz képest., Annak szemléltetése, hogy az EXACTMATCH (top) és a Bowtie ‘s aligner (bottom) hogyan működik, ha nincs pontos egyezés a “ggta” lekérdezéshez, de van egy-eltérés igazítás, ha az ” a “helyébe” g ” lép. A dobozos számpár a mátrixsorok tartományait jelöli, kezdve az addig megfigyelt utótaggal. A piros X jelöli, ahol az algoritmus találkozik egy üres tartomány vagy megszakítja (mint EXACTMATCH) vagy backtracks (mint az inexact algoritmus). Egy zöld pipa, ahol az algoritmus talál egy nonempty tartományban határoló egy vagy több előfordulását jelentendő igazítás a lekérdezés.,
röviden, Bowtie minőségtudatos, mohó, randomizált, mélység-az első keresés a lehetséges igazítások területén. Ha érvényes igazítás létezik, akkor a Bowtie megtalálja (a következő részben tárgyalt backtrack mennyezetre figyelemmel). Mivel a keresés kapzsi, a Bowtie által tapasztalt első érvényes igazítás nem feltétlenül lesz a “legjobb” az eltérések száma vagy a minőség szempontjából., A felhasználó utasíthatja Bowtie-t, hogy folytassa a keresést, amíg be nem tudja bizonyítani, hogy az általa jelentett igazítás “a legjobb” az eltérések száma szempontjából (a –best opció használatával). Tapasztalataink szerint ez a mód kétszer-háromszor lassabb, mint az alapértelmezett mód. Arra számítunk, hogy a gyorsabb alapértelmezett mód előnyben részesül a nagy újraszekvenálási projekteknél.
a felhasználó választhatja a Bowtie-t is, hogy az összes nyomvonalakat egy meghatározott számig (opció-k) vagy minden olyan nyomvonalakig jelentse, amelyek nem korlátozzák a számot (opció-a) egy adott olvasáshoz., Ha a keresés során Bowtie talál n lehetséges igazítások egy adott sor helyettesítések,de a felhasználó kérte csak K nyomvonalakat, ahol K < N, Bowtie jelentést k n nyomvonalakat véletlenszerűen kiválasztott. Vegye figyelembe,hogy ezek a módok sokkal lassabbak lehetnek, mint az alapértelmezett. Tapasztalataink szerint például a-k 1 több mint kétszer olyan gyors, mint a-k 2.
túlzott visszalépés
az eddig leírtak szerint az aligner egyes esetekben olyan szekvenciákkal találkozhat, amelyek túlzott visszahúzódást okoznak., Ez akkor fordul elő, amikor az aligner erőfeszítéseinek nagy részét eredménytelenül visszavonja a lekérdezés 3 ” végéhez közeli pozíciókba. Bowtie enyhíti a túlzott visszalépést a “kettős indexelés” új technikájával. A genom két indexe jön létre: az egyik a genom BWT-jét tartalmazza, az úgynevezett “forward” index, a második pedig a genom BWT-jét tartalmazza, amelynek karakterszekvenciája fordított (nem fordított), az úgynevezett “tükör” index. Ha látni szeretné, hogy ez hogyan segít, fontolja meg egy megfelelő házirendet, amely lehetővé teszi az összehangolás egyik eltérését., Az egy eltéréssel való érvényes igazítás két eset egyikébe esik, amelyek szerint az olvasás fele tartalmazza az eltérést. A Bowtie a két esetnek megfelelő két fázisban folytatódik. Az 1. fázis betölti a forward indexet a memóriába, és meghívja az aligner-t azzal a megkötéssel, hogy nem helyettesítheti a lekérdezés jobb felében lévő pozíciókat. A 2. fázis a tükörindexet használja, és a fordított lekérdezés igazítóját hívja meg, azzal a kényszerrel, hogy az aligner nem helyettesítheti a fordított lekérdezés jobb felében lévő pozíciókat (az eredeti lekérdezés bal fele)., A jobb oldali visszahúzás korlátai megakadályozzák a túlzott visszahúzódást, míg a két fázis és két index használata teljes érzékenységet tart fenn.
sajnos nem lehet teljes mértékben elkerülni a túlzott visszalépést, ha az igazítások két vagy több eltérést engedélyeznek. Kísérleteink során megfigyeltük, hogy a túlzott visszahúzás csak akkor jelentős, ha az olvasásnak sok rossz minőségű pozíciója van, és nem igazodik vagy rosszul igazodik a referenciához., Ezek az esetek olvasásonként több mint 200 visszalépést válthatnak ki, mivel az alacsony minőségű pozíciók sok jogi kombinációját meg kell vizsgálni, mielőtt az összes lehetőség kimerülne. Ezt a költséget úgy csökkentjük, hogy korlátozzuk a keresés befejezése előtt engedélyezett visszalépések számát (alapértelmezett: 125). A határérték megakadályozza, hogy néhány legitim, alacsony minőségű igazítást jelentsenek, de elvárjuk, hogy ez a legtöbb alkalmazás számára kívánatos kompromisszum legyen.,
szakaszos Maq-szerű keresés
Bowtie lehetővé teszi a felhasználó számára, hogy válassza ki a több eltérés megengedett (alapértelmezett: két) a kiváló minőségű végén egy olvasási (alapértelmezett: az első 28 bázisok), valamint a maximális elfogadható minőségi távolság a teljes igazítás (alapértelmezett: 70). A minőségi értékek a phred definícióját követik, ahol p a hiba valószínűsége, Q = – 10log p.
mind az olvasás, mind annak fordított kiegészítése a referenciához való igazításra jelölt. Az egyértelműség kedvéért ez a vita csak az előretekintő irányultságot veszi figyelembe., Lásd az 1. kiegészítő adatfájlt (2.Kiegészítő vita) a fordított KOMPLEMENT beépítésének magyarázatához.
az első 28 bázisok a kiváló minőségű végén az olvasási nevezik a “mag”. A mag két félből áll: a 14 bp a kiváló minőségű végén (általában az 5 “végén), a 14 bp pedig az alacsony minőségű végén, a” hi-half “-nek, illetve a “lo-half” -nek nevezik., Feltételezve, hogy az alapértelmezett politika (két eltérés megengedett, a seed), bemutatandó igazítás fog esni egy négy esetben: nem eltéréseket, a mag (az 1); nincs eltérés a hi-fél, egy vagy két eltéréseket, a lo-fele (case 2); nincs eltérés a lo-fél, egy vagy két eltérések a hi-fél (case 3); valamint egy eltérés hi-fele, az egyik eltérés a lo-fél (4. eset).
minden eset lehetővé teszi, hogy az olvasás nem megfelelő részében tetszőleges számú eltérés legyen, és minden esetben a minőségi távolságkorlátozás is fennáll.,
a Bowtie algoritmus három fázisból áll, amelyek váltakoznak az elő-és tükörindexek használata között, amint azt a 3. ábra szemlélteti. Az 1. fázis a tükörindexet használja, és felhívja az Igazítót, hogy megtalálja az 1.és 2. eset igazításait. A 2.és 3. szakasz együttműködik a 3. eset igazításainak megtalálásában: a 2. szakasz csak a hi-half és a 3. szakaszban találja meg a részleges igazításokat a teljes igazításokra. Végül a 3. fázis felhívja az Igazítót, hogy keresse meg a 4. eset igazítását.,

a MAQ-szerű politika Bowtie algoritmusának három fázisa. A háromfázisú megközelítés igazításokat talál a két nem megfelelő esetekre 1 nak nek 4 miközben minimalizálja a visszahúzást. Az 1. fázis a tükörindexet használja, és felhívja az Igazítót, hogy megtalálja az 1.és 2. eset igazításait. Fázis 2, illetve 3 együttműködni, hogy megtalálja nyomvonalakat az esetben 3: 2. Szakasz megállapítja, részleges nyomvonalakat a diszkrepanciák csak a hi-fele, fázis 3 megpróbálja kiterjeszteni a részleges nyomvonalakat a teljes nyomvonalakat., Végül a 3. fázis felhívja az Igazítót, hogy keresse meg a 4. eset igazítását.
teljesítmény eredmények
a Bowtie teljesítményét az 1000 Genomes project pilot (National Center for Biotechnology Information Short Read Archive:SRR001115) olvasásával értékeltük. Összesen 8,84 millió olvasás, körülbelül egy sáv adat egy Illumina eszköz, vágták 35 bp és igazodik az emberi referencia Genom . Eltérő rendelkezés hiányában az olvasási adatokat nem szűrjük vagy módosítjuk (a vágás mellett) az archívumban megjelenő módon., Ez azt eredményezi, hogy az olvasás körülbelül 70-75% – a igazodik valahol a genomhoz. Tapasztalataink szerint ez jellemző az archívumból származó nyers adatokra. Az agresszívebb szűrés magasabb összehangolási sebességhez és gyorsabb összehangoláshoz vezet.
az összes futást egyetlen CPU-n hajtották végre. Bowtie speedups számított aránya falióra igazítás alkalommal. Mind a falióra, mind a CPU-idő azt bizonyítja, hogy a bemeneti/kimeneti terhelés és a CPU-állítás nem jelentős tényező.
a Bowtie index felépítéséhez szükséges idő nem került bele a Bowtie futási időkbe., A Versengő eszközökkel ellentétben a Bowtie számos igazítási futáson keresztül újra felhasználhatja a referencia Genom előre kiszámított indexét. Arra számítunk, hogy a legtöbb felhasználó egyszerűen letölti az ilyen indexeket egy nyilvános tárolóból. A Bowtie oldal az emberi, a csimpánz, az egér, a kutya, a patkány és az Arabidopsis thaliana genomes, valamint még sokan mások jelenlegi építményeit mutatja be.
Eredmények születtek a két hardver platformok: asztali munkaállomás 2,4 GHz-es Intel Core 2 processzor, 2 GB RAM; nagy-memória szerver egy négy magos 2.4 GHz-es AMD Opteron processzor, 32 GB RAM-mal., Ezeket ” PC “- nek, illetve “szervernek” nevezik. Mind a PC, mind a szerver futtatja a Red Hat Enterprise Linuxot a 4. kiadásként.
összehasonlítása SOAP és Maq
Maq egy népszerű aligner, hogy az egyik leggyorsabban versengő nyílt forráskódú eszközök összehangolására millió Illumina olvas az emberi genom. A SOAP egy másik nyílt forráskódú eszköz, amelyet rövid olvasású projektekben jelentettek be és használtak .
az 1. táblázat a Bowtie v0.9.6, a SOAP V1.10 és a Maq V0.6.6 teljesítményét és érzékenységét mutatja be. A SOAP nem futtatható a számítógépen, mert a SOAP memória lábnyoma meghaladja a számítógép fizikai memóriáját. A szappan.,contig ” változata a szappan bináris használták. Összehasonlításképpen SZAPPANNAL, Csokornyakkendő hivatkozott a ‘-v ‘2’, hogy utánozza SZAPPAN alapértelmezett megfelelő politika (amely lehetővé teszi, akár két eltérések a felszerelését, valamint figyelmen kívül hagyja a minőségi értékek), illetve ‘–maxns 5’ szimulálni SZAPPAN alapértelmezett politika a szűrés ki olvas öt vagy több nem-bizalom alapjait. A Maq összehasonlítás Bowtie fut az alapértelmezett politika, amely utánozza Maq alapértelmezett politika, amely lehetővé teszi akár két eltérés az első 28 bázisok és érvényesítése teljes határérték 70 az összeg a minőségi értékek minden nem megfelelő olvasási pozíciók., Hogy Csokornyakkendő van memóriát több hasonló Maq van, Csokornyakkendő hivatkoznak a ‘-z’ opciót minden kísérletet annak érdekében, hogy csak az előre, vagy tükör index rezidens a memória egy időben.
Az igazított leolvasások száma azt jelzi, hogy a szappan (67,3%) és a Bowtie-v 2 (67,4%) hasonló érzékenységgel rendelkezik. A szappannal vagy Bowtie-val igazított olvasmányok közül 99,7% – ot mindkettő igazított, 0,2% – ot Bowtie igazított, de nem szappan, 0,1% – ot pedig szappan igazított, de nem Bowtie. A Maq (74,7%) és a Bowtie (71,9%) szintén nagyjából hasonló érzékenységgel rendelkezik, bár a Bowtie 2,8% – kal elmarad., A Maq vagy a Bowtie által igazított olvasások közül 96,0% – ot mindkettő igazított, 0,1% – ot Bowtie igazított, de nem Maq, 3,9% – ot pedig Maq igazított, de nem Bowtie. A MAQ által leképezett olvasások közül, de nem Bowtie, szinte mindegyik a MAQ igazítási algoritmusának rugalmasságának köszönhető, amely lehetővé teszi egyes igazítások számára, hogy három eltérés legyen a magban. A Maq által leképezett, de nem Bowtie által készített olvasás fennmaradó része Bowtie hátsó mennyezetének köszönhető.
Maq dokumentációja megemlíti, hogy a “poli-a-leleteket” tartalmazó olvasmányok ronthatják Maq teljesítményét., A 2. táblázat a Bowtie és a Maq teljesítményét és érzékenységét mutatja be, amikor az olvasási készletet a MAQ ‘catfilter’ parancsával szűrjük a poli-a műtárgyak kiküszöbölésére. A szűrő megszünteti 438,145 ki 8,839,010 olvasás. Más kísérleti paraméterek megegyeznek az 1.táblázatban szereplő kísérletekével, és a Bowtie és a Maq viszonylagos érzékenységére vonatkozó megfigyelések itt is érvényesek.
olvasási hossz és teljesítmény
ahogy a szekvenálási technológia javul, az olvasási hossz a mai nyilvános adatbázisokban gyakran látott 30-bp-ről 50-bp-re növekszik., A Bowtie, a Maq és a SOAP support akár 1,024, 63, illetve 60 bp hosszúságú, a Maq 0.7.0 verziók pedig később támogatják az olvasási hosszúságot 127 bp-ig. A 3. táblázat mutatja teljesítmény eredményeket, ha a három eszközök minden használt align három különböző a 2 M untrimmed olvas, egy 36-bp készlet, 50-bp meghatározott, illetve a 76-bp állítsa be, hogy az emberi genom a szerver platform. Minden 2 M-es készletet véletlenszerűen mintavételeznek egy nagyobb készletből(NCBI rövid olvasási Archívum: SRR003084 36-bp, SRR003092 50-bp, SRR003196 76-bp)., Az olvasókat úgy mintavételezték, hogy a 2 m-es három készletnek egységes bázis-hibaaránya legyen, az alap-Fred tulajdonságokból számítva. Minden olvasás áthalad Maq “catfilter”.
Bowtie mind a Maq-szerű alapértelmezett módban, mind a szappanszerű ‘-v 2’ módban fut. Bowtie is kap a “- z ” lehetőséget annak biztosítására, hogy csak az előre vagy tükör index rezidens memória egy időben. Maq v0.7. 1 használták helyett Maq v0.6.6 a 76-bp készlet, mert v0.6.,Az 6 nem tudja összehangolni a 63 bp-nél hosszabb olvasásokat. Szappan nem fut a 76-bp készlet, mert nem támogatja olvas hosszabb, mint 60 bp.
Az eredmények azt mutatják, hogy a Maq algoritmusa összességében jobban skálázik, mint a Bowtie vagy a SOAP. Azonban a Bowtie szappanszerű “- v 2 ” módban is nagyon jól skálázik. Bowtie az alapértelmezett Maq-szerű mód mérlegek is 36-bp 50-bp olvasás, de lényegesen lassabb 76-bp olvasás, bár ez még mindig több, mint egy nagyságrenddel gyorsabb, mint a Maq.,
párhuzamos teljesítmény
az Igazítás párhuzamosítható az egyidejű Keresési szálak közötti olvasások terjesztésével. Bowtie lehetővé teszi a felhasználó számára, hogy adja meg a kívánt szálak száma (option-p); Bowtie majd elindítja a megadott számú szálak segítségével a pthreads könyvtár. Bowtie szálak szinkronizálni egymással, amikor lekérése olvasás, kimenet eredmények közötti váltás indexek, és végző különböző formái globális könyvelés, mint például a jelölés olvasási “kész”., Ellenkező esetben a szálak szabadon működhetnek párhuzamosan, jelentősen felgyorsítva a több processzormaggal rendelkező számítógépek összehangolását. Az index memória képét minden szál megosztja, így a lábnyom nem növekszik jelentősen, ha több szálat használnak. A 4. táblázat a négymagos szerveren futó Bowtie V0.9.6 teljesítményeredményeit mutatja egy, kettő és négy szálon.,
Index building
Bowtie egy rugalmas indexelő algoritmust használ, amely konfigurálható a memória használata és a futási idő közötti kereskedelemre. Az 5. táblázat szemlélteti ezt a kompromisszumot a teljes emberi referencia Genom indexelésekor (NCBI build 36.3, contigs). A futásokat a szerver platformon hajtották végre. Az indexelőt négyszer futtatták, különböző felső határértékekkel a memóriahasználatra.,
a jelentett idők kedvezően hasonlítanak az igazítás során indexelést végző versengő eszközök igazítási idejéhez. Kevesebb, mint 5 óra szükséges ahhoz, hogy Bowtie mind az 1000 Genomprojektből (NCBI Short Read Archive:SRR001115) 8, 84 millió olvasással egész emberi indexet készítsen és lekérdezzen egy szerveren, több mint hatszor gyorsabban, mint az egyenértékű Maq run., Az alsó-legtöbb sor azt mutatja, hogy a Bowtie indexelő, megfelelő érvekkel, elég memória-hatékony ahhoz, hogy egy tipikus munkaállomáson 2 GB RAM-mal működjön. Az 1.kiegészítő adatfájl (3. és 4. Kiegészítő megbeszélések) ismerteti a kapott index algoritmusát és tartalmát.
Software
a Bowtie C++ nyelven íródott és a SeqAn könyvtárat használja . A MAQ mapping formátumba konvertáló Maq kódot használ.