Bowtie indeksit viittaus genomin käyttäen järjestelmää, joka perustuu Burrows-Wheeler-muunnos (BWT) ja FM-indeksi . Rusettia indeksi ihmisen genomin sopii 2.2 GB levyllä ja on muisti jalanjälki niin vähän kuin 1.3 GT linjaus aikaa, jolloin sitä voidaan tiedustella työasemalla, jossa on alle 2 GT RAM-muistia.,
yleinen tapa etsiä FM-indeksi on tarkka-matching algoritmi Ferragina ja Manzini . Bowtie ei yksinkertaisesti hyväksy tätä algoritmia, koska täsmällinen vastaavuus ei mahdollista sekvensointivirheiden tai geneettisten muunnosten tekemistä. Esittelemme kaksi romaani laajennuksia, jotka tekevät tekniikka soveltaa lyhyen lue linjaus: laatu-tietoisia, vetäytymistä algoritmi, joka mahdollistaa kysynnän ja tarjonnan kohtaamattomuus ja suosii laadukkaita linjauksia; ja ’double indeksointi’, strategia välttää liiallista vetäytymistä., Bowtie aligner seuraa politiikkaa samanlainen Maq on, että se mahdollistaa pienen lukumäärän epäsuhta sisällä korkea-laatu jokaisen lukea, ja se asettaa ylärajan summa laatu arvot ristiriitaiset linjaus kantoja.
Burrows-Wheeler indexing
BWT on tekstin merkkien käännettävä permutaatio. Vaikka alun perin kehitetty osana tiedon pakkaus, BWT-pohjainen indeksointi mahdollistaa suurten tekstejä voidaan hakea tehokkaasti pieni muisti jalanjälki., Se on ollut soveltaa bioinformatiikan sovelluksia, mukaan lukien oligomeerin laskenta , koko-genomin linjaus , laatoitus microarray luotaimen suunnittelu ja Smith-Waterman linjaus on ihmisen kokoinen viite .
tekstin t, BWT(T), Burrows-Wheeler-muunnos on rakennettu seuraavasti. Merkki $ on liitteenä T, jossa $ ei ole T ja on kirjaimet vähemmän kuin kaikki merkit T. Burrows-Wheeler-matriisi T on rakennettu matriisi, jonka rivit sisältävät kaikki sykliset kierrot T$. Rivit lajitellaan tämän jälkeen sanakirjallisesti., BWT (T) on merkkien sarja Burrows-Wheeler-matriisin oikeassa sarakkeessa (Kuva 1a). BWT(T) pituus on sama kuin alkuperäisen tekstin T.
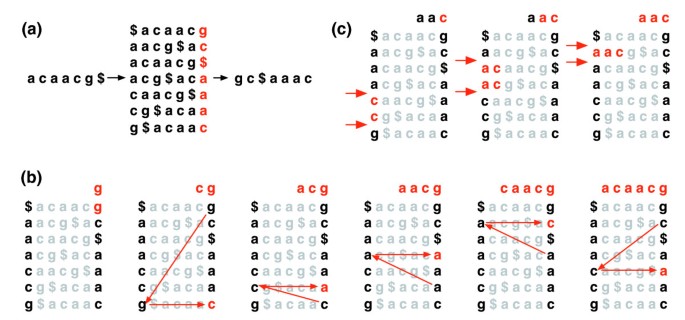
Burrows-Wheeler-muunnos. (a) Burrows-Wheeler-matriisi ja muutos ’acaacg’. (b) Toimet, joita EXACTMATCH tunnistaa erilaisia rivejä, ja siten asetettu viite päätteitä, etuliitteenä ’aac’., (c) UNPERMUTE toistuvasti koskee viime ensimmäinen (LF) kartoitus palauttaa alkuperäisen tekstin (punainen top line) alkaen Burrows-Wheeler-muunnos (musta oikeanpuoleisessa sarakkeessa).
Tämä matriisi on ominaisuus nimeltä ’viime ensimmäinen (LF) kartoitus’. I esiintyminen merkki X viimeinen sarake vastaa saman tekstin luonnetta ith esiintyminen X ensimmäinen sarake. Tämä ominaisuus pohjautuu algoritmeihin, jotka käyttävät BWT-indeksiä navigoidakseen tai etsiäkseen tekstiä., Kuva 1b kuvaa UNPERMUTEA, algoritmia, joka soveltaa LF-kartoitusta toistuvasti T: n uudelleen luomiseen BWT: stä(T).
LF-kartoitusta käytetään myös tarkassa sovituksessa. Koska matriisi on lajiteltu kirjaimet, rivit alkavat tietyssä järjestyksessä näkyvät peräkkäin. Sarjan vaiheet, EXACTMATCH-algoritmi (Kuva 1c) laskee alue matriisin rivit joiden alussa on peräkkäin enää päätteitä kyselyn. Kussakin vaiheessa koko alue joko kutistuu tai pysyy samana., Kun algoritmi on valmis, rivit, joiden alussa on S0 (koko kysely) vastaa täsmälleen esiintymiä kyselyn tekstiä. Jos alue on tyhjä, teksti ei sisällä kyselyn. UNPERMUTE johtuu Burrows ja Wheeler ja EXACTMATCH että Ferragina ja Manzini . Lisätietoja on lisätietotiedostossa 1 (Lisäkeskustelu 1).
Haku epätarkka linjaukset
EXACTMATCH on riittävän lyhyt lukea linjaus, koska rinnastuksia voi olla epätasapaino, joka voi johtua sekvensointi virheet, aito eroja viite-ja query-organismien, tai molemmat., Esittelemme linjaus algoritmi, joka tekee vetäytymistä haku nopeasti löytää linjauksia, jotka täyttävät tietyn politiikan linjaus. Kunkin merkin lukea on numeerinen laatu arvo, jossa pienemmät arvot osoittavat suurempi todennäköisyys sekvensointi virhe. Meidän linjaus politiikka sallii rajoitetun määrän epäsuhta ja mieluummin linjauksia, joissa summa laatu arvot kaikki ristiriitaiset kannat on alhainen.
haku etenee samalla tavalla EXACTMATCH, laskettaessa matriisi vaihtelee peräkkäin enää kyselyn päätteitä., Jos alue on tyhjä (pääte ei esiinny tekstiä), niin algoritmi voi valita jo sovitettu kysely asema ja korvata eri pohja on, esittelyssä epäsuhta osaksi linjaus. EXACTMATCH haku jatkuu heti korvaavan kannan jälkeen. Algoritmi valitsee vain ne vaihdot, jotka ovat yhdenmukaisia linjaus politiikan ja jotka tuottavat muutettu pääte, joka esiintyy ainakin kerran tekstissä. Jos on useita ehdokas korvaaminen kantoja, niin algoritmi ahnaasti valitsee aseman, jossa minimaalinen laadun arvo.,
Vetäytymistä skenaarioita pelata puitteissa pino rakenne, joka kasvaa kun uusia korvaaminen on otettu käyttöön ja kutistuu, kun oikaisin hylkää kaikki ehdokas linjauksia vaihdot tällä hetkellä pino. Kuvassa 2 on kuvaus siitä, miten etsintä voisi edetä.
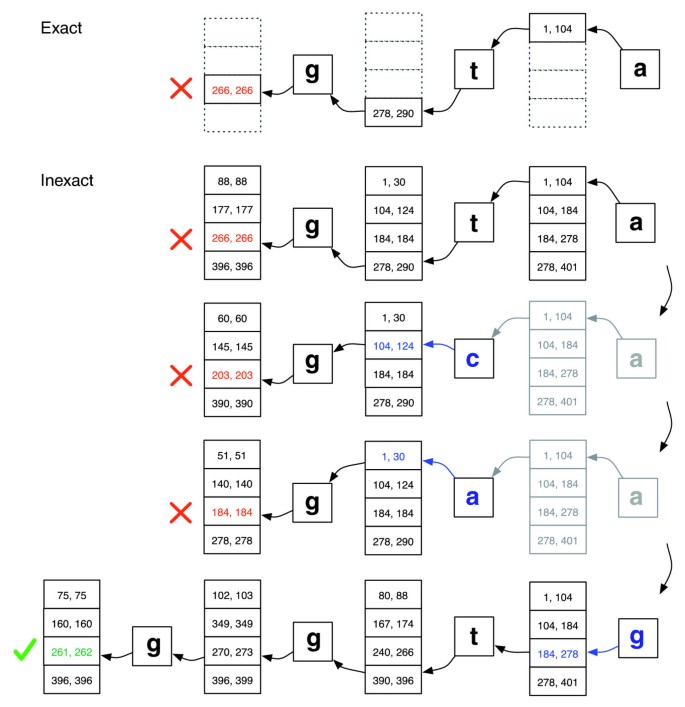
Tarkka matching vastaan epätarkka linjaus., Esimerkki siitä, kuinka EXACTMATCH (top) ja Rusetti on aligner (pohja) jatkaa, kun ei ole tarkka ottelu kysely ’ggta’, mutta siellä on yksi-epäsuhta linjaus, kun ” a ”on korvattu ”g”. Ruudulliset numeroparit tarkoittavat matriisirivien vaihteluvälejä, jotka alkavat siihen asti havaitulla loppuliitteellä. Punainen X marks, jos algoritmi havaitsee tyhjä alue ja joko keskeyttää (kuten EXACTMATCH) tai palaa (kuten epätarkka algoritmi). Vihreä valintamerkit, jossa algoritmi etsii epätyhjä alue rajataan yksi tai useampi poikkeamista on raportoitava linjaus kyselyn.,
lyhyesti sanottuna, Rusetti tekee laatu-tietoisia, ahne, satunnaistettu, syvyys-ensin-haun kautta tilaa ja mahdollisia linjauksia. Jos voimassa linjaus on olemassa, niin Bowtie löytää sen (jollei takakatto käsitellään seuraavassa osassa). Koska haku on ahne, ensimmäinen voimassa oleva linjaus kohtaamista Bowtie ei välttämättä ”paras” kannalta lukumäärän epäsuhta tai laatua., Käyttäjä voi ohjata Bowtie jatkaa etsimistä, kunnes se voi todistaa, että se linjaus raportit on ”paras” lukumäärän epäsuhta (käyttäen vaihtoehto-paras). Kokemuksemme mukaan tämä tila on kahdesta kolmeen kertaa oletustilaa hitaampi. Odotamme, että nopeampi oletustila on parempi suurissa uudelleen sekvensointiprojekteissa.
käyttäjä voi myös valita Bowtie ilmoittaa kaikki linjaukset jopa tietty määrä (vaihtoehto-k) tai kaikki linjauksia ole rajoitettu määrä (optio -a) tietyn lukea., Jos aikana sen haku Bowtie toteaa, N mahdollista linjauksia tietyn joukko vaihdot, mutta käyttäjä on pyytänyt, vain K linjauksia, missä K < N, Rusetti ilmoittaa K N linjauksia valittu sattumanvaraisesti. Huomaa, että nämä tilat voivat olla paljon hitaampia kuin oletusarvo. Kokemuksemme mukaan esimerkiksi-k 1 on yli kaksi kertaa nopeampi kuin-k 2.
liiallinen perääntyminen
toistaiseksi kuvattu aligner voi joissain tapauksissa kohdata jaksoja, jotka aiheuttavat liiallista perääntymistä., Tämä tapahtuu, kun aligner käyttää suurimman osan vaivannäöstään tuloksettomasti taaksepäin asemiin lähellä kyselyn 3 ’ loppua. Bowtie lieventää liiallista perääntymistä uudella ”double indexing” – tekniikalla. Kaksi indeksit genomin ovat luotu: yksi, joka sisältää BWT genomin, nimeltään ”eteenpäin” – indeksi, ja toinen sisältää BWT-genomin kanssa sen luonne järjestys päinvastaiseksi (ei käänteinen täydentää) kutsutaan ’peili’ indeksi. Nähdä, miten tämä auttaa, harkitse matching politiikkaa, joka mahdollistaa yhden epäsuhta linjaus., Kelvollinen linjaus yhteen epäsuhtaan osuu jompaankumpaan kahdesta tapauksesta, joiden mukaan puolet lukemasta sisältää epäsuhtan. Bowtie etenee kahdessa vaiheessa, jotka vastaavat näitä kahta tapausta. Vaihe 1 kuormia eteenpäin indeksi muistiin ja vetoaa aligner kanssa rajoitus, että se voi korvata tällä tehtävissä kysely on oikea puoli. Vaihe 2 käyttää peili-indeksi ja vetoaa aligner on päinvastainen kyselyn, jossa rajoitus että aligner voi korvata tällä tehtävissä käänteinen kysely on oikea puoli (alkuperäinen kysely on vasen puoli)., Oikeanpuoleiseen peräänajoon liittyvät rajoitukset estävät liiallisen perääntymisen, kun taas kahden vaiheen ja kahden indeksin käyttö pitää täyden herkkyyden.
Valitettavasti, se ei ole mahdollista välttää liiallista vetäytymistä täysin, kun linjaukset eivät saa olla kaksi tai enemmän epäsuhta. Meidän kokeiluja, olemme havainneet, että liiallinen vetäytyminen on merkittävä vain silloin, kun luku on paljon huonolaatuisia kantoja ja ei tasaa tai tasaa huonosti viite., Näissä tapauksissa voi laukaista yli 200 perääntyy kohti lukea, koska on olemassa monia oikeudellisia yhdistelmiä huonolaatuisia kantoja tutkittava, ennen kuin kaikki mahdollisuudet on käytetty loppuun. Lievennämme tätä kustannuksia asettamalla rajoituksen sallittujen taustatukien määrälle ennen haun lopettamista (oletus: 125). Raja estää joitakin oikeutettuja, huonolaatuisia linjauksia on raportoitu, mutta odotamme, että tämä on toivottavaa, kauppa-off useimpiin sovelluksiin.,
Vaiheittain Maq-kuten haku
Bowtie avulla käyttäjä voi valita lukumäärän epäsuhta sallittua (oletus: kaksi) high-quality loppuun lukea (oletus: ensimmäinen 28 emäkset) sekä suurin hyväksyttävä laatu etäisyys yleinen linjaus (oletus: 70). Laatu-arvojen oletetaan seuraa määritelmä PHRED , jossa p on todennäköisyys, että virhe ja Q = -10log p.
Sekä lukea ja sen käänteinen täydentää ovat ehdokkaita linjaus viite. Selvyyden vuoksi tässä keskustelussa tarkastellaan vain eteenpäin suuntautumista., Katso Lisätiedot tiedosto 1 (Täydentävä Keskustelu 2) selvitys siitä, miten käänteinen täydentää on sisällytetty.
ensimmäinen 28 tukikohtia laadukkaita loppuun lukea nimitetään ’siemen’. Siemen koostuu kahdesta puolikkaasta: 14 bp laadukkaita loppuun (yleensä 5′ pää) ja 14 bp low-laatu-end, kutsutaan ’hi-puoli” ja ”lo-puoli’, vastaavasti., Olettaen, default policy (kaksi kohtaanto sallittua siemen), raportoitava linjaus putoaa yksi neljä tapausta: n kohtaanto seed (asia 1); ei kohtaanto hi-puoli, yksi tai kaksi kohtaanto-lo-puoli (tapaus 2); ei kohtaanto-lo-puoli, yksi tai kaksi kohtaanto hi-puolella (tapaus 3), ja yksi epäsuhta hi-puoli, yksi epäsuhta lo-puoli (tapaus 4).
kaikki tapaukset mahdollistavat lukemattomien osien epäsuhtien määrän ja kaikkiin tapauksiin sovelletaan myös laatuetäisyysrajoitusta.,
Bowtie algoritmi koostuu kolmesta vaiheesta, jotka vuorotellen käyttäen eteenpäin ja peili indeksit, kuten Kuvassa 3. Vaihe 1 käyttää peili-indeksi ja vetoaa aligner löytää linjauksia tapauksissa 1 ja 2. Vaiheet 2 ja 3 yhteistyössä löytää linjauksia tapaus 3: Vaihe 2-löytää osittainen linjaukset kohtaanto vain hi-puoli ja vaihe 3 yrittää laajentaa niitä osittainen linjauksia täyteen linjauksia. Lopuksi Vaihe 3 kutsuu alignerin etsimään lähetyksiä tapaukseen 4.,

kolme vaihetta Bowtie algoritmi Maq-kuten politiikka. Kolmivaiheinen lähestymistapa löytää lähetyksiä kahden kohtaanto-tapauksia 1-4 ja minimoi perääntyminen. Vaihe 1 käyttää peili-indeksi ja vetoaa aligner löytää linjauksia tapauksissa 1 ja 2. Vaiheet 2 ja 3 yhteistyössä löytää linjauksia tapaus 3: Vaihe 2-löytää osittainen linjaukset kohtaanto vain hi-puoli, ja vaihe 3 yrittää laajentaa niitä osittainen linjauksia täyteen linjauksia., Lopuksi Vaihe 3 kutsuu alignerin etsimään lähetyksiä tapaukseen 4.
tuloksia
arvioida suorituskykyä Bowtie käyttämällä lukee 1000 Genomia-projektin pilotti (National Center for Biotechnology Information Lyhyen Lue Arkisto:SRR001115). Yhteensä 8.84 miljoonaa lukee, noin yksi kaista tietoja Illumina väline, karsittiin 35 bp ja linjassa ihmisen viite genomin . Ellei toisin ilmoiteta, lukea tietoja ei suodateta tai muutettu (paitsi leikkaus) siitä, miten ne näkyvät arkistossa., Tämä johtaa noin 70-75 prosenttiin lukemista, jotka suuntautuvat johonkin genomiin. Kokemuksemme mukaan tämä on tyypillistä arkiston raakadatalle. Aggressiivisempi suodatus johtaa korkeampiin linjausnopeuksiin ja nopeampaan linjaukseen.
kaikki juoksut suoritettiin yhdellä suorittimella. Bowtie speedups laskettiin seinäkellon linjausaikojen suhteena. Sekä seinäkello – että SUORITINAJAT on annettu osoittamaan, että tulo – / Lähtökuormitus ja SUORITINKUORMITUS eivät ole merkittäviä tekijöitä.
Bowtie-indeksin rakentamiseen tarvittava aika ei sisältynyt Bowien juoksuajoihin., Toisin kuin kilpailevissa työkaluissa, Bowtie voi käyttää uudelleen vertailuperimän valmiiksi laskettua indeksiä monissa linjausajoissa. Odotamme, että useimmat käyttäjät yksinkertaisesti lataavat tällaiset indeksit julkisesta arkistosta. Bowtie-sivusto tarjoaa indeksit ihmisen, simpanssin, hiiren, koiran, rotan ja Arabidopsis thaliana genomien nykyisille rakenteille sekä monille muille.
Tulokset saatiin kaksi hardware-alustat: työpöydän työasema, jossa 2,4 GHz: n Intel Core 2-prosessori ja 2 GT RAM-muistia; ja suuri-muisti-palvelin, jossa on neljä-core 2,4 GHz: n AMD Opteron-prosessori ja 32 GT RAM-muistia., Näitä merkitään vastaavasti ” PC ” ja ”server”. Sekä PC että palvelin ajaa Red Hat Enterprise Linux julkaisuna 4.
Verrattuna SAIPPUALLA ja Maq
Maq on suosittu aligner, joka on keskuudessa nopein kilpailevia avoimen lähdekoodin työkaluja kohdistamalla miljoonia Illumina lukee ihmisen genomin. Saippua on toinen avoimen lähdekoodin työkalu, jota on raportoitu ja käytetty lyhytlukuisissa projekteissa .
Taulukko 1 esittelee Bowtie v0.9.6: n, SOAP v1.10: n ja Maq v0.6.6: n suorituskyvyn ja herkkyyden. Saippuaa ei voitu ajaa PC: llä, koska saippuan muistijalanjälki ylittää PC: n fyysisen muistin. Saippua.,contigin versiota SAIPPUABINAARIOSTA käytettiin. Vertailun SAIPPUALLA, Bowtie oli vedonnut kanssa ’-v 2’ matkia SAIPPUAA, default matching politiikka (joka mahdollistaa jopa kaksi kohtaanto linjaus ja sivuutetaan laatu arvot), ja ’–maxns 5’ simuloida SAIPPUAA, default policy suodatus ulos lukee viisi tai useampia ei-luottamuksen perustaa. Sillä Maq vertailu Bowtie on ajaa sen default politiikkaa, joka jäljittelee Maq-oletus politiikan jolloin jopa kaksi kohtaanto ensimmäinen 28 emäkset ja täytäntöönpanon yleinen raja on 70 summa laatu arvot kaikki ristiriitaiset lukea kantoja., Jotta Rusetti on muistia enemmän verrattavissa Maq on, Bowtie vedotaan kanssa ’-z’ vaihtoehto kaikki kokeet sen varmistamiseksi, että vain eteen-tai peili-indeksi on muistissa yhdellä kertaa.
reads aligned-luku kertoo, että saippuan (67,3%) ja Bowtie-v 2: n (67,4%) herkkyys on vertailukelpoinen. Osa lukee tietokoneella joko SAIPPUAA tai Rusetti, 99,7 prosenttia olivat linjassa sekä, 0,2 prosenttia olivat linjassa Bowtie, mutta ei SAIPPUAA, ja 0,1% olivat linjassa SAIPPUA mutta ei Bowtie. Maq (74.7%) ja Bowtie (71.9%) on myös lähes vastaava herkkyys, vaikka Bowtie laahaa 2,8 prosenttia., Osa lukee tietokoneella joko Maq-tai Rusetti, 96.0% olivat linjassa sekä, 0.1% olivat linjassa Bowtie mutta ei Maq, ja 3,9% oli linjassa Maq mutta ei Bowtie. Osa lukee kartoitettu Maq mutta ei Bowtie, lähes kaikki ovat koska joustavuutta Maq-on linjaus algoritmi, jonka avulla joitakin linjauksia on kolme kohtaanto siemen. Loput lukee kartoitettu Maq mutta ei Bowtie johtuvat Bowtie on vetäytymistä kattoon.
Maqin dokumenteissa mainitaan, että ”poly-a-artefakteja” sisältävä teksti voi heikentää Maqin suoritusta., Taulukossa 2 esitetään Bowien ja Maq: n suorituskyky ja herkkyys, kun lukusarja suodatetaan Maq: n catfilter-komennolla poly-a-artefaktien poistamiseksi. Suodatin poistaa 438 145 8 839 010: stä lukemasta. Muut kokeelliset parametrit ovat samat kuin kokeissa Taulukossa 1, ja samoin huomautuksia, suhteellinen herkkyys Bowtie ja Maq päde täällä.
Lue pituus ja suorituskyky
Kuten sekvensointi teknologia parantaa, lue pituudet kasvavat yli 30-bp-50-bp nähdään yleisesti julkisia tietokantoja tänään., Bowtie, Maq, ja SAIPPUA tukea lukee pituudet jopa 1,024, 63 ja 60 bp, vastaavasti, ja Maq-versiot 0.7.0 ja myöhemmin tukea lukea pituudet jopa 127 bp. Taulukossa 3 esitetään tulokset, kun kolme työkalut ovat jokaisen käytetään yhdenmukaistaa kolme sarjaa 2 M leikkaamaton lukee, 36-bp-setti, 50-bp asettaa ja 76-bp asettaa, ihmisen genomin palvelimen alustan. Jokaisen sarjan 2 M on satunnaisesti poimittu otokseen suurempi joukko (NCBI Lyhyen Lue Arkisto: SRR003084 36-bp, SRR003092 50-bp, SRR003196 76-bp)., Lukemat otettiin siten, että kolmella 2 M: n joukolla on yhdenmukainen per perusvirhetaso, joka lasketaan per-base Phred-ominaisuuksista. Kaikki lukee läpi Maqin ”catfilter”.
Bowtie on ajaa sekä sen Maq-kuin default-tilassa ja sen SOAP-kuten ’-v-2’ – tilassa. Bowtie on myös antanut ’-z’ – vaihtoehto varmistaa, että vain eteen-tai peili-indeksi on muistissa yhdellä kertaa. Maq v0. 7.1: tä käytettiin Maq v0.6.6: n sijasta 76-bp-setissä, koska v0.6.,6 ei pysty kohdistamaan lukua pitempään kuin 63 bp. SAIPPUA ei toimi 76-bp asettaa, koska se ei tue lukee kauemmin kuin 60 bp.
tulokset osoittavat, että Maq-algoritmi skaalaa paremmin yleistä enää lukea pitkälle kuin Bowtie tai SAIPPUAA. SAIPPUAMAISESSA ”- v 2 ” – tilassa Bowtie kuitenkin myös skaalautuu erittäin hyvin. Bowtie sen default Maq-kuten tila skaalautuu hyvin 36-bp-50-bp lukee, mutta on huomattavasti hitaampi 76-bp lukee, vaikka se on vielä enemmän kuin kertaluokkaa nopeammin kuin Maq.,
Rinnakkainen suoritus
Kohdistus voidaan parallelized jakamalla lukee koko samanaikainen haku kierteet. Bowtie antaa käyttäjälle mahdollisuuden määrittää haluttu määrä lankoja (vaihtoehto-p); Bowtie käynnistää määritetyn kierteiden määrän pthreads-kirjastolla. Bowtie kierteet synkronoida keskenään, kun noudettaessa lukee, syöttöä tulokset, vaihto indeksit, ja suorittaa erilaisia muotoja global kirjanpito, kuten merkintä lukea ”valmis”., Muussa tapauksessa langat ovat vapaita toimimaan rinnakkain, mikä nopeuttaa merkittävästi yhdenmukaistamista tietokoneissa, joissa on useita prosessoriytimiä. Indeksin muistikuva on kaikkien kierteiden yhteinen, joten jalanjälki ei kasva merkittävästi, kun käytetään useita kierteitä. Taulukossa 4 on esitetty Bowtie v0.9.6: n suoritustulokset nelisydämisellä palvelimella yhdellä, kahdella ja neljällä langalla.,
Hakemisto rakentaminen
Bowtie käyttää joustava indeksointi algoritmi, joka voidaan konfiguroida kaupan pois välillä muistin käyttö ja käynnissä aikaa. Taulukko 5 havainnollistaa tätä vaihtokauppaa indeksoitaessa koko ihmisen referenssigenomia (NCBI build 36.3, contigs). Ajot suoritettiin palvelinalustalla. Indeksiä ajettiin neljä kertaa eri ylärajoilla muistin käytölle.,
raportoitu kertaa vertailla suotuisasti kanssa linjaus kertaa kilpailevien työkaluja, jotka suorittaa indeksointi aikana linjaus. Vähemmän kuin 5 tuntia tarvitaan Bowtie sekä rakentaa ja kyselyn koko-ihmisen indeksi 8.84 miljoonaa lukee 1000 Genome project (NCBI Lyhyen Lue Arkisto:SRR001115) palvelimelle, yli kuusinkertaiseksi nopeammin kuin vastaava Maq ajaa., Pohja-useimmat rivi osoittaa, että Bowtie indexer, asianmukaisia perusteluja, on muisti-tarpeeksi tehokas toimimaan tyypillinen työasema, jossa on 2 GT RAM-muistia. Lisätietotiedosto 1 (lisäkeskustelut 3 ja 4) selittää algoritmin ja tuloksena olevan indeksin sisällön.
ohjelmisto
Bowtie on kirjoitettu C++: lla ja käyttää SeqAn-kirjastoa . Muunnin Maq kartoitus muoto käyttää koodia Maq.