Bowtie indekserer reference genom ved hjælp af en ordning, der er baseret på en Burrows-Wheeler transformation (BWT) og FM-indeks . En Bowtie-indekset for det menneskelige genom passer 2,2 GB på harddisken og har en hukommelse fodaftryk af så lidt som 1,3 GB på tilpasning tid, så det, der forespørges på en arbejdsstation med under 2 GB RAM.,
den almindelige metode til søgning i et fm-indeks er den nøjagtige matchende algoritme for Ferragina og man .ini . Bo .tie vedtager ikke blot denne algoritme, fordi nøjagtig matchning ikke tillader sekventeringsfejl eller genetiske variationer. Vi introducerer to nye udvidelser, der gør teknikken anvendelig til justering af kort læsning: en kvalitetsbevidst backtracking-algoritme, der tillader uoverensstemmelser og favoriserer justeringer af høj kvalitet; og ‘dobbelt indeksering’, en strategi for at undgå overdreven backtracking., Bo .tie aligner følger en politik, der ligner Ma. ‘ er, idet den tillader et lille antal uoverensstemmelser inden for slutningen af hver læsning af høj kvalitet, og den placerer en øvre grænse for summen af kvalitetsværdierne ved uoverensstemmende justeringspositioner.
Burro .s-indeheeler indeksering
B .t er en reversibel permutation af tegnene i en tekst. Selvom det oprindeligt blev udviklet inden for rammerne af datakomprimering, tillader B .t-baseret indeksering, at store tekster søges effektivt i et lille hukommelsesfodaftryk., Det er blevet anvendt til bioinformatik applikationer, herunder oligomer optælling, hele-genom tilpasning, flisebelægning microarray sonde design, og Smith-Wateraterman tilpasning til en human størrelse reference .
den Burro .s-Wheelheeler transformation af en tekst T, B .t(T), er konstrueret som følger. Tegnet $, der er føjet til T, hvor $ er ikke i T og er lexicographically mindre end alle tegn i T. Burrows-Wheeler matrix af T er konstrueret som matrix, hvis rækker omfatter alle cyklisk rotationer af T$. Rækkerne sorteres derefter leksikografisk., B .t (T) er rækkefølgen af tegn i den yderste højre kolonne af Burro .s-Wheelheeler Matri. (figur 1a). BWT(T) har samme længde som den oprindelige tekst T.
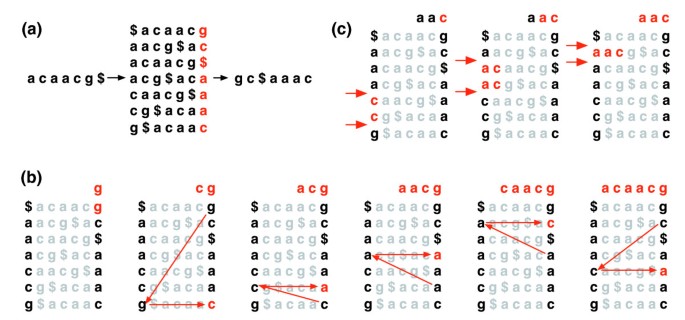
Burrows-Wheeler omdanne. a) Burro .s-Wheelheeler Matri Theen og transformation for ‘acaacg’. (b) de skridt, der er taget af E .actmatch til at identificere rækken af rækker, og dermed sæt af reference suffikser, præfikset af ‘aac’., (C) UNPERMUTE gentagne gange anvender den sidste første (LF) kortlægning at genvinde den oprindelige tekst (i rød på den øverste linje) fra Burro .s-Wheelheeler transform (i sort i yderste højre kolonne).
denne Matri.har en egenskab kaldet ‘last first (LF) mapping’. Den ith forekomst af tegn in i den sidste kolonne svarer til den samme tekst tegn som ith forekomst af character i den første kolonne. Denne egenskab ligger til grund for algoritmer, der bruger B .t-indekset til at navigere eller søge i teksten., Figur 1b illustrerer UNPERMUTE, en algoritme, der anvender LF-kortlægningen gentagne gange for at genskabe T fra B .t(t).
LF-kortlægningen bruges også i nøjagtig matchning. Da Matri theen sorteres leksikografisk, vises rækker, der begynder med en given sekvens, fortløbende. I en række trin beregner e .actmatch-algoritmen (figur 1c) rækkevidden af Matri rowsrækker, der begynder med successivt længere suffikser af forespørgslen. Ved hvert trin krymper størrelsen af området enten eller forbliver den samme., Når algoritmen er færdig, rækker, der begynder med S0 (hele forespørgslen) svarer til nøjagtige forekomster af forespørgslen i teksten. Hvis området er tomt, indeholder teksten ikke forespørgslen. UNPERMUTE, der kan henføres til Burrows Wheeler og EXACTMATCH at Ferragina og Manzini . Se yderligere datafil 1 (supplerende Diskussion 1) For detaljer.
Søgning efter upræcis linjeføringer
EXACTMATCH er utilstrækkelig til korte læs tilpasning, fordi alignments kan indeholde paradokser, som kan være på grund af sekventering fejl, ægte forskelle mellem reference-og forespørgsel organismer, eller begge dele., Vi introducerer en justeringsalgoritme, der udfører en backtracking-søgning for hurtigt at finde justeringer, der tilfredsstiller en specificeret justeringspolitik. Hvert tegn i en læsning har en numerisk kvalitetsværdi, med lavere værdier, der indikerer en højere sandsynlighed for en sekventeringsfejl. Vores justeringspolitik tillader et begrænset antal uoverensstemmelser og foretrækker justeringer, hvor summen af kvalitetsværdierne på alle uoverensstemmende positioner er lav.
søgningen fortsætter på samme måde som e .actmatch, beregning af Matri rangesområder for successivt længere forespørgselssuffikser., Hvis området bliver tomt (et suffiks ikke forekommer i teksten), kan algoritmen vælge en allerede matchet forespørgselsposition og erstatte en anden base der og indføre en uoverensstemmelse i justeringen. E .actmatch-søgningen genoptages fra lige efter den substituerede position. Algoritmen vælger kun de substitutioner, der er i overensstemmelse med justeringspolitikken, og som giver et modificeret suffiks, der forekommer mindst en gang i teksten. Hvis der er flere kandidatsubstitutionspositioner, vælger algoritmen grådigt en position med en minimal kvalitetsværdi.,Backtracking scenarier afspilles inden for rammerne af en stakstruktur, der vokser, når en ny substitution introduceres og krymper, når aligneren afviser alle kandidatjusteringer for substitutionerne, der i øjeblikket er på stakken. Se figur 2 for en illustration af, hvordan søgningen kan fortsætte.
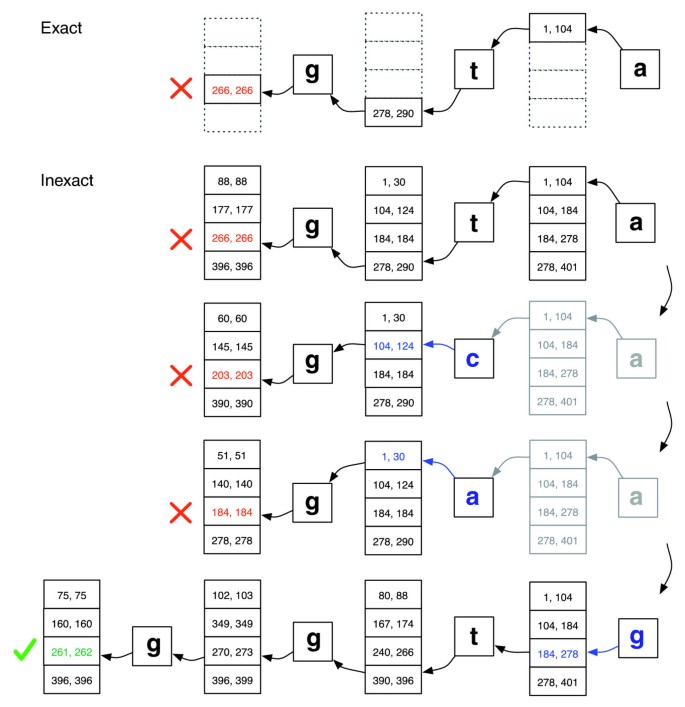
Præcis matcher versus upræcis tilpasning., Illustration af, hvordan EXACTMATCH (øverst) og Bowtie er aligner (nederst) fortsæt, når der ikke er nogen eksakt match query ‘ggta”, men der er en en-mismatch justering, når ‘a’ er erstattet af ‘g’. Bo .ed par af tal angiver intervaller af Matri rows rækker begynder med suffikset observeret op til dette punkt. En rød marks markerer, hvor algoritmen støder på et tomt område og enten aborts (som i E .actmatch) eller backtracks (som i den upræcise algoritme). En grøn markering, hvor algoritmen finder en nonempty område afgrænser en eller flere forekomster af en Indberetningspligtig justering for forespørgslen.,
kort sagt udfører bo .tie en kvalitetsbevidst, grådig, randomiseret, dybdegående søgning gennem rummet af mulige justeringer. Hvis der findes en gyldig justering, finder bo .tie det (underlagt backtrack-loftet diskuteret i det følgende afsnit). Fordi søgningen er grådig, vil den første gyldige justering, som bo .tie møder, ikke nødvendigvis være den ‘bedste’ med hensyn til antal uoverensstemmelser eller med hensyn til kvalitet., Brugeren kan instruere bo .tie at fortsætte med at søge, indtil det kan bevise, at enhver justering det rapporterer er ‘bedst’ med hensyn til antallet af uoverensstemmelser (ved hjælp af indstillingen –bedst). Efter vores erfaring er denne tilstand to til tre gange langsommere end standardtilstanden. Vi forventer, at hurtigere standardtilstand vil blive foretrukket til store re-sekventering projekter.
brugeren kan også vælge bo .tie at rapportere alle justeringer op til et bestemt antal (option-k) eller alle justeringer uden grænse for antallet (option-A) for en given læsning., Hvis der i løbet af sin søgning Bowtie finder N mulige linjeføringer for et givet sæt af udskiftninger, men brugeren har anmodet K linjeføringer, hvor K < N, Bowtie vil rapportere K i N justeringer, der er udvalgt tilfældigt. Bemærk, at disse tilstande kan være meget langsommere end standardindstillingen. Efter vores erfaring er for eksempel-K 1 mere end dobbelt så hurtig som-K 2.
overdreven backtracking
aligneren som beskrevet hidtil kan i nogle tilfælde støde på sekvenser, der forårsager overdreven backtracking., Dette sker, når aligner tilbringer det meste af sin indsats frugtløst backtracking til positioner tæt på 3′ slutningen af forespørgslen. Bo .tie afbøder overdreven backtracking med den nye teknik ‘dobbelt indeksering’. To indekser af genomet er oprettet: en, der indeholder BWT af genomet, kaldet ‘forward’ – indekset, og en anden, der indeholder BWT af genom med dets karakter sekvens omvendt (ikke omvendt suppleret) kaldet ‘spejl’ – indekset. For at se, hvordan dette hjælper, skal du overveje en matchende politik, der tillader en uoverensstemmelse i justeringen., En gyldig justering med en uoverensstemmelse falder ind i et af to tilfælde, hvorefter halvdelen af læsningen indeholder uoverensstemmelsen. Bo .tie fortsætter i to faser svarende til disse to tilfælde. Fase 1 indlæser fremad indeks i hukommelsen og påberåber sig aligner med den begrænsning, at det ikke kan erstatte på positioner i forespørgslen højre halvdel. Fase 2 bruger spejlindekset og påberåber aligneren på den omvendte forespørgsel, med den begrænsning, at aligneren muligvis ikke erstatter positioner i den omvendte forespørgsels højre halvdel (den oprindelige forespørgsels venstre halvdel)., Begrænsningerne for backtracking i højre halvdel forhindrer overdreven backtracking, mens brugen af to faser og to indekser opretholder fuld følsomhed.
det er desværre ikke muligt at undgå overdreven backtracking fuldt ud, når justeringer er tilladt at have to eller flere uoverensstemmelser. I vores eksperimenter har vi observeret, at overdreven backtracking kun er signifikant, når en læsning har mange lavkvalitetspositioner og ikke justerer eller justerer Dårligt til referencen., Disse tilfælde kan udløse over 200 backtracks pr. læsning, fordi der er mange juridiske kombinationer af lavkvalitetspositioner, der skal udforskes, før alle muligheder er opbrugt. Vi mindsker denne omkostning ved at håndhæve en grænse for antallet af backtracks, der er tilladt, før en søgning afsluttes (standard: 125). Grænsen forhindrer, at der rapporteres om nogle legitime justeringer af lav kvalitet, men vi forventer, at dette er en ønskelig afvejning for de fleste applikationer.,
Gradvis af maq-som søgning
Bowtie giver brugeren mulighed for at vælge antallet af uoverensstemmelser tilladt (standard: to) i høj kvalitet slutningen af en læse (standard: de første 28 baser), samt maksimal acceptabel kvalitet afstand af den samlede tilpasning (standard: 70). Kvalitet værdier antages at følge definitionen i PHRED , hvor p er sandsynligheden for fejl og Q = -10log p.
Både læse og dens omvendt supplement er kandidater til tilpasning til reference. For klarhedens skyld betragter denne diskussion kun den fremadrettede orientering., Se yderligere datafil 1 (supplerende Diskussion 2) for en forklaring af, hvordan det omvendte komplement er indarbejdet.
de første 28 baser på den høje kvalitet ende af læsningen betegnes ‘frø’. Frøet består af to halvdele: 14 bp på den høje kvalitet ende (normalt 5′ ende) og 14 bp på den lave kvalitet ende, betegnes henholdsvis ‘hi-half’ og ‘lo-half’., Hvis man antager standardpolitikken (to uoverensstemmelser, der er tilladt i frøet), falder en rapporterbar justering i et af fire tilfælde: ingen uoverensstemmelser i frø (sag 1); ingen uoverensstemmelser i hi-half, en eller to uoverensstemmelser i lo-half (sag 2); ingen uoverensstemmelser i lo-half, en eller to uoverensstemmelser i hi-half (sag 3); og en uoverensstemmelse i hi-half, en uoverensstemmelse i lo-half (sag 4).
alle sager tillader et hvilket som helst antal uoverensstemmelser i den ikke-seedede del af læsningen, og alle sager er også underlagt kvalitetsafstandsbegrænsningen.,
bo .tie-algoritmen består af tre faser, der skifter mellem at bruge frem-og spejlindekserne, som illustreret i figur 3. Fase 1 bruger spejl indeks og påberåber aligner at finde alignments for cases 1 og 2. Faser 2 og 3 Samarbejd om at finde justeringer til sag 3: Fase 2 finder kun delvise justeringer med uoverensstemmelser i hi-halvdelen, og fase 3 forsøger at udvide disse delvise justeringer til fulde justeringer. Endelig påberåber fase 3 aligneren for at finde tilpasninger til sag 4.,

De tre faser af Bowtie algoritme for af maq-lignende politik. En trefaset tilgang finder justeringer for to-mismatch tilfælde 1 til 4 samtidig minimere backtracking. Fase 1 bruger spejl indeks og påberåber aligner at finde alignments for cases 1 og 2. Faser 2 og 3 samarbejder om at finde justeringer til sag 3: Fase 2 finder kun delvise justeringer med uoverensstemmelser i hi-halvdelen, og fase 3 forsøger at udvide disse delvise justeringer til fulde justeringer., Endelig påberåber fase 3 aligneren for at finde tilpasninger til sag 4.
resultater
Vi har vurderet udførelsen af Bowtie hjælp læser fra de 1.000 Genomer pilot projekt (National Center for Biotechnology Information Kort Læse Arkiv:SRR001115). I alt 8, 84 millioner læser, omkring en bane med data fra et Illumina-instrument, blev trimmet til 35 bp og justeret til det menneskelige referencegenom . Medmindre andet er angivet, filtreres eller ændres læste data ikke (udover trimning) fra, hvordan de vises i arkivet., 70% til 75% af læsningerne, der tilpasser sig et sted til genomet. Efter vores erfaring er dette typisk for rå data fra arkivet. Mere aggressiv filtrering fører til højere justeringshastigheder og hurtigere justering.
alle kørsler blev udført på en enkelt CPU. Bo .tie speedups blev beregnet som et forhold mellem vægurjusteringstider. Både væg-ur og CPU tider er givet til at demonstrere, at input / output belastning og CPU påstand er ikke væsentlige faktorer.
den tid, der kræves for at opbygge bo .tie-indekset, var ikke inkluderet i Bo .tie-løbstiderne., I modsætning til konkurrerende værktøjer kan bo .tie genbruge et forudberegnet indeks til referencegenomet på tværs af mange justeringskørsler. Vi forventer, at de fleste brugere blot vil do .nloade sådanne indekser fra et offentligt lager. Bo .tie-.ebstedet indeholder indekser for aktuelle bygninger af mennesket, chimpanse, mus, hund, rotte, og Arabidopsis thaliana genomer, såvel som mange andre.
Resultater blev opnået på to hardware-platforme: en stationær arbejdsstation med 2,4 GHz Intel Core 2 processor og 2 GB RAM, og en stor hukommelse server med en fire-kerne 2.4 GHz AMD Opteron-processor og 32 GB RAM., Disse betegnes henholdsvis ‘PC ‘ og’ server’. Både PC og server køre Red Hat Enterprise Linu.som release 4.
sammenligning med sæbe og Ma.
Ma. er en populær aligner, der er blandt de hurtigste konkurrerende open source-værktøjer til at tilpasse millioner af Illumina læser til det menneskelige genom. SOAP er et andet open source-værktøj, der er rapporteret og brugt i kortlæste projekter .
tabel 1 viser ydeevnen og følsomheden af Bo .tie v0.9.6, SOAP v1.10 og Ma.v0.6.6. SOAP kunne ikke køres på PC ‘en, fordi SOAP’ s hukommelsesfodaftryk overstiger PC ‘ ens fysiske hukommelse. Sæben.,contig ‘ version af SOAP binary blev brugt. Til sammenligning med SÆBE, Bowtie blev startet med ‘-v 2’ for at efterligne SÆBE standard matchende politik (som giver mulighed for op til to for at udligne forskelle i tilpasningen og ikke tager hensyn til kvalitet, værdier), og med ‘–maxns 5’ til at simulere SÆBE standard politik for at filtrere læser med fem eller mere ikke-tillid baser. Til MA. – sammenligningen køres bo .tie med sin standardpolitik, som efterligner Ma .s standardpolitik om at tillade op til to uoverensstemmelser i de første 28 baser og håndhæve en samlet grænse på 70 på summen af kvalitetsværdierne på alle uoverensstemmende læsepositioner., For at gøre bo .ties hukommelsesfodaftryk mere sammenligneligt med Ma. ‘er, påberåbes bo .tie med indstillingen’- z ‘ i alle eksperimenter for at sikre, at kun fremad-eller spejlindekset er bosiddende i hukommelsen på .n gang.
antallet af aflæsninger justeret indikerer, at sæbe (67,3%) og Bo .tie-v 2 (67,4%) har sammenlignelig følsomhed. For den læser afstemt med enten SÆBE eller Bowtie, 99.7% blev justeret både 0.2% var afstemt med Bowtie, men ikke SÆBE, og 0,1% var afstemt med SÆBE, men ikke Bowtie. Ma. (74.7%) og Bo .tie (71.9%) har også nogenlunde sammenlignelig følsomhed, selvom bo .tie halter med 2.8%., For den læser tilpasses ved enten af maq eller Bowtie, 96.0% blev justeret både 0.1% var afstemt med Bowtie, men ikke af maq og 3,9% blev justeret ved af maq men ikke Bowtie. Af de læsninger, der er kortlagt af Ma., men ikke bo .tie, skyldes næsten alle en fleksibilitet i Ma .s justeringsalgoritme, der gør det muligt for nogle justeringer at have tre uoverensstemmelser i frøet. Resten af læsningerne kortlagt af Ma., men ikke bo .tie skyldes Botietie ‘ s backtracking loft.
Ma. ‘s dokumentation nævner, at læsninger, der indeholder’ poly-A-artefakter’, kan forringe Ma. ‘ s ydeevne., Tabel 2 viser ydeevne og følsomhed bo .tie og Ma.når læse sæt filtreres ved hjælp af Ma. ‘s’ catfilter ‘ kommando til at fjerne poly-a artefakter. Filteret eliminerer 438,145 ud af 8,839,010 læser. Andre eksperimentelle parametre er identiske med eksperimenterne i tabel 1, og de samme observationer om den relative følsomhed af Bo .tie og Ma.gælder her.
Læs længde og ydeevne
efterhånden som sekventeringsteknologien forbedres, vokser læselængderne ud over 30-bp til 50-bp, der ofte ses i offentlige databaser i dag., Bo .tie, Ma., og SOAP support læser længder op til 1.024, 63 og 60 bp, henholdsvis, og Ma. versioner 0.7.0 og nyere Støtte læse længder op til 127 bp. Tabel 3 viser ydeevneresultater, når de tre værktøjer hver bruges til at justere tre sæt med 2 M untrimmed læsninger, et 36-bp sæt, et 50-bp sæt og et 76-bp sæt, til det menneskelige genom på serverplatformen. Hvert sæt på 2 M udtages tilfældigt fra et større sæt (NCBI Kortlæsningsarkiv: SRR003084 til 36-BP, SRR003092 til 50-bp, SRR003196 til 76-BP)., Læsninger blev samplet således, at de tre sæt 2 M har ensartet fejlfrekvens pr.base, som beregnet ud fra PR. Alle læsninger passerer gennem Ma.’catfilter’.
Bowtie drives både af maq-som standard-tilstand og i sin SÆBE-lignende ‘-v 2’ – tilstand. Bo .tie er også givet ‘-z’ mulighed for at sikre, at kun fremad eller spejl indeks er bosiddende i hukommelsen på .n gang. Ma.v0.7.1 blev brugt i stedet for Ma.v0.6.6 til 76-BP-sættet, fordi v0. 6.,6 kan ikke justere læser længere end 63 bp. Sæbe blev ikke kørt på 76 – BP sæt, fordi det ikke understøtter læser længere end 60 BP.
resultaterne viser, at Ma. ‘ s algoritme generelt skalerer bedre til længere læselængder end bo .tie eller SOAP. Bo .tie i sæbe-lignende ‘-v 2’ – tilstand skalerer dog også meget godt. Bowtie i sin standard af maq-lignende tilstand skalaer godt fra 36-bp til 50-bp læser, men er væsentligt langsommere for 76-bp læser, selv om det stadig er mere end en størrelsesorden hurtigere end af maq.,
Parallel ydeevne
justering kan paralleliseres ved at distribuere læser på tværs af samtidige søgetråde. Bo .tie giver brugeren mulighed for at angive et ønsket antal tråde (option-p); bo .tie lancerer derefter det angivne antal tråde ved hjælp af pthreads biblioteket. Bo .tie tråde synkroniseres med hinanden, når du henter læser, udsender resultater, skifter mellem indekser og udfører forskellige former for global bogføring, såsom at markere en læsning som ‘udført’., Ellers er trådene fri til at fungere parallelt, hvilket væsentligt fremskynder tilpasningen på computere med flere processorkerner. Hukommelsesbilledet af indekset deles af alle tråde, og derfor øges fodaftrykket ikke væsentligt, når der bruges flere tråde. Tabel 4 viser resultater for at køre Bowtie v0.9.6 på fire-core server med en, to og fire tråde.,
Indeks bygning
Bowtie bruger en fleksibel indeksering algoritme, der kan være konfigureret til at trade-off mellem hukommelse og køretid. Tabel 5 illustrerer denne afvejning ved indeksering af hele det menneskelige referencegenom (NCBI build 36.3, contigs). Kørsler blev udført på serverplatformen. Indekseren blev kørt fire gange med forskellige øvre grænser for hukommelsesforbrug.,
Den rapporterede gange sammenligne sig med tilpasning gange af konkurrerende værktøjer, der udfører indeksering under justeringen. Mindre end 5 timer er påkrævet for Bo .tie at både Bygge og forespørge et hel-menneskeligt indeks med 8.84 millioner læser fra 1,000 Genome project (NCBI Short Read Archive:SRR001115) på en server, mere end seks gange hurtigere end den tilsvarende Ma.run., Den nederste række illustrerer, at bo .tie-indekseren med passende argumenter er hukommelseseffektiv nok til at køre på en typisk arbejdsstation med 2 GB RAM. Yderligere datafil 1 (supplerende diskussioner 3 og 4) forklarer algoritmen og indholdet af det resulterende indeks.
Soft .are
bo Bowtie er skrevet i C++ og bruger se .an biblioteket . Konverteren til MA.kortlægning format bruger kode fra Ma..