Motýlek indexy referenčního genomu pomocí systém založený na Burrows-Wheelerova transformace (BWT) a FM index . Bowtie index pro lidský genom se vejde do 2.2 GB na disku a má paměťovou stopu až 1.3 GB v době zarovnání, což umožňuje dotazování na pracovní stanici s méně než 2 GB RAM.,
běžnou metodou vyhledávání v indexu FM je algoritmus přesné shody Ferraginy a Manzini . Bowtie tento algoritmus jednoduše nepřijímá, protože přesné párování neumožňuje sekvenování chyb nebo genetických variací. Představujeme dvě nové rozšíření, které se na techniku použitelné pro krátká čtení zarovnání: kvalitní-aware backtracking algoritmus, který umožňuje nesouladu a podporuje vysoce kvalitní zarovnání; a ‚double indexování‘, strategii, aby se zabránilo nadměrné backtracking., Bowtie aligner se řídí politikou podobnou Maq, v tom, že umožňuje malý počet neshod v rámci vysoce kvalitního konce každého čtení, a klade horní hranici součtu hodnot kvality v neodpovídajících polohách zarovnání.
Burrows-Wheeler indexing
BWT je reverzibilní permutace znaků v textu. Přestože byl původně vyvinut v rámci komprese dat, indexování založené na BWT umožňuje efektivní vyhledávání velkých textů v malé paměťové stopě., To byl aplikován na bioinformatika aplikací, včetně oligomeru počítání , whole-genome zarovnání , obklady microarray konstrukce sondy , a Smith-Waterman zarovnání do lidské velikosti referenční .
Burrows-Wheeler transformace textu t, BWT (T), je konstruována následovně. Znak $ je připojena k T, kde $ není v T a je lexikograficky menší než všechny postavy v T. Burrows-Wheeler matice T je konstruován jako matice, jejíž řádky tvoří všechny cyklické rotace T$. Řádky jsou pak řazeny lexikograficky., BWT (T) je posloupnost znaků v pravém sloupci matice Burrows-Wheeler (obrázek 1a). BWT(T) má stejnou délku jako původní text T.
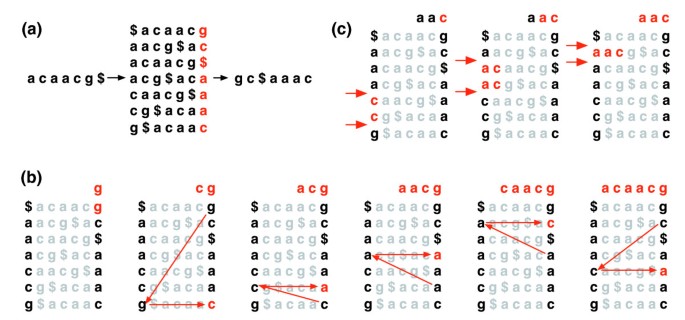
Burrows-Wheeler transform. a) matice Burrows-Wheeler a transformace pro „acaacg“. b) kroky podniknuté společností EXACTMATCH k určení rozsahu řádků, a tedy souboru referenčních přípon, předponovaných „aac“., (c) UNPERMUTE opakovaně používá poslední první (LF) mapování obnovit původní text (červeně na horním řádku) z Burrows-Wheeler transformace (v černé barvě v pravém sloupci).
tato matice má vlastnost nazvanou „last first (LF) mapping“. Ith výskyt znaku X v posledním sloupci odpovídá stejnému textovému znaku jako Ith výskyt X v prvním sloupci. Tato vlastnost je základem algoritmů, které používají index BWT pro navigaci nebo vyhledávání textu., Obrázek 1b ilustruje UNPERMUTE, algoritmus, který opakovaně používá mapování LF k opětovnému vytvoření T Z BWT (T).
mapování LF se také používá při přesném porovnávání. Protože matice je řazena lexikograficky, řádky začínající danou sekvencí se objevují postupně. V sérii kroků vypočítá algoritmus EXACTMATCH (obrázek 1C) rozsah řádků matice začínající postupně delšími příponami dotazu. V každém kroku se velikost rozsahu buď zmenšuje, nebo zůstává stejná., Po dokončení algoritmu odpovídají řádky začínající S0 (celý dotaz) přesným výskytům dotazu v textu. Pokud je rozsah prázdný, text neobsahuje dotaz. UNPERMUTE lze přičíst Burrows a Wheeler a EXACTMATCH na Ferragina a Manzini . Podrobnosti naleznete v doplňkovém datovém souboru 1 (doplňková diskuse 1).
Vyhledávání pro nepřesné zarovnání
EXACTMATCH je dostatečné pro krátké čtení zarovnání, protože zarovnání může obsahovat nesoulad, což může být způsobeno sekvenování chyby, skutečné rozdíly mezi referenčními a dotaz organismů, nebo obojí., Představujeme algoritmus zarovnání, který provádí zpětné vyhledávání, aby rychle našel zarovnání, které splňují zadanou politiku zarovnání. Každý znak v čtení má číselnou hodnotu kvality, s nižšími hodnotami označujícími vyšší pravděpodobnost chyby sekvenování. Naše politika zarovnání umožňuje omezený počet neshod a upřednostňuje zarovnání, kde je součet hodnot kvality na všech neshodných pozicích nízký.
vyhledávání probíhá podobně jako EXACTMATCH, výpočet rozsahů matic pro postupně delší přípony dotazu., Pokud se rozsah vyprázdní (přípona se v textu nevyskytuje), může algoritmus vybrat již odpovídající pozici dotazu a nahradit tam jinou základnu a do zarovnání zavést nesoulad. Hledání EXACTMATCH pokračuje od těsně po substituované pozici. Algoritmus vybírá pouze ty substituce, které jsou v souladu s politikou zarovnání a které přinášejí upravenou příponu, ke které dochází alespoň jednou v textu. Pokud existuje více kandidátských substitučních pozic, pak algoritmus lačně vybere pozici s minimální hodnotou kvality.,
Backtracking scénáře hrát v rámci stack struktury, která roste, když se nová náhrada je zaveden a zmenšuje, když se vyrovnávač odmítá všechny kandidátské zarovnání pro substituce v současné době na zásobníku. Viz Obrázek 2 pro ilustraci toho, jak by mohlo vyhledávání pokračovat.
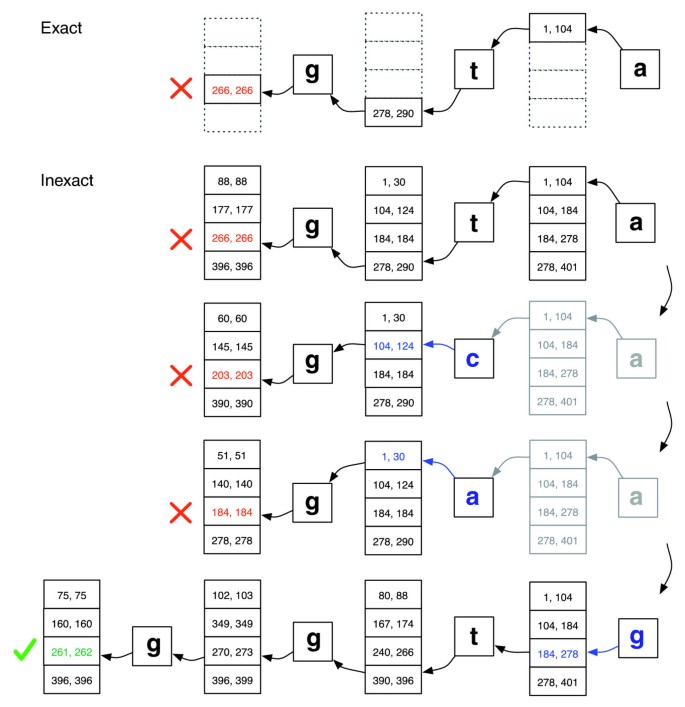
Přesná shoda versus nepřesné zarovnání., Ilustrace toho, jak EXACTMATCH (horní) a Bowtie je aligner (dolní) postupovat, když neexistuje přesná shoda pro dotaz ‚ggta‘, ale tam je zarovnání jeden nesoulad, když ‚a‘ je nahrazen ‚g‘. Boxované páry čísel označují rozsahy řádků matice začínající příponou pozorovanou až do tohoto bodu. Červený křížek označuje místo, kde algoritmus narazí na prázdnou oblast a buď přeruší (jako v EXACTMATCH), nebo ustoupí (jako v nepřesné algoritmus). Zelené zaškrtnutí, kde algoritmus najde neprázdný rozsah vymezující jeden nebo více výskytů vykazovaného zarovnání pro dotaz.,
stručně řečeno, Motýlek provádí kvality-aware, chamtivý, randomizované, hloubka-nejprve prohledávat prostor možných zarovnání. Pokud existuje platné zarovnání, pak ho Bowtie najde (s výhradou zpětného stropu popsaného v následující části). Protože hledání je chamtivý, první platný zarovnání, s nimiž se setkávají Motýlek nemusí být nutně „nejlepší“, pokud jde o počet neshod nebo z hlediska kvality., Uživatel může instruovat Bowtie pokračovat v hledání, dokud nemůže prokázat, že jakékoli zarovnání, které hlásí, je „nejlepší“, pokud jde o počet neshod (pomocí volby-nejlepší). Podle našich zkušeností je tento režim dvakrát až třikrát pomalejší než výchozí režim. Očekáváme, že rychlejší výchozí režim bude preferován pro velké projekty re-sekvenování.
uživatel se také může rozhodnout, že Bowtie nahlásí všechny zarovnání až na zadané číslo (option-K) nebo všechny zarovnání bez omezení počtu (option-a) pro dané čtení., Pokud se v průběhu jeho hledání Motýlek najde N možné zarovnání pro danou množinu substitucí, ale uživatel požadoval pouze K zarovnání, kde K < N, Motýlek bude hlásit K N zarovnání vybrána náhodně. Všimněte si, že tyto režimy mohou být mnohem pomalejší než výchozí. Podle našich zkušeností je například-k 1 více než dvakrát rychlejší než-k 2.
Nadměrné backtracking
vyrovnávač, jak je popsáno tak daleko může v některých případech setkat sekvence, které způsobují nadměrné backtracking., K tomu dochází, když vyrovnávač tráví většinu svého úsilí marně ustupování do pozice blízko k 3′ konci dotazu. Bowtie zmírňuje nadměrné backtracking s novou technikou ‚dvojité indexování‘. Dva indexy genomu jsou vytvořeny: jeden obsahující BWT genomu, tzv. „vpřed“ index, a druhá obsahující BWT genomu s jeho charakter pořadí obrácené (ne reverzní doplněna) s názvem „zrcadlo“ index. Chcete-li zjistit, jak to pomáhá, zvažte odpovídající politiku, která umožňuje jeden nesoulad v zarovnání., Platné zarovnání s jedním nesouladem spadá do jednoho ze dvou případů, podle nichž polovina čtení obsahuje nesoulad. Bowtie probíhá ve dvou fázích odpovídajících těmto dvěma případům. Fáze 1 načte dopředný index do paměti a vyvolá zarovnávač s omezením, které nemusí nahradit na pozicích v pravé polovině dotazu. Fáze 2 používá zrcadlo index a vyvolá vyrovnávač na obrácený dotaz, s tím omezením, že vyrovnávač nemusí nahradit na pozice v obrácené dotazu pravou polovinu (původní dotaz je levá polovina)., Omezení na ustupování do pravé poloviny se zabránilo nadměrné backtracking, vzhledem k tomu, že použití dvou fázích a dvou indexů udržuje plnou citlivost.
bohužel není možné vyhnout se nadměrnému zpětnému sledování, pokud je zarovnání povoleno mít dva nebo více nesouladů. V našich experimentech jsme pozorovali, že nadměrné backtracking je významný pouze při čtení má mnoho nekvalitních pozicích a není zarovnat nebo špatně vyrovnává na odkaz., V těchto případech může vyvolat více než 200 ustoupí za číst, protože existuje mnoho právních kombinace low-kvalitní pozic, které mají být prozkoumány, než všechny možnosti jsou vyčerpány. My zmírnit tyto náklady prosazováním limit na počet ustoupí před tím, než je vyhledávání ukončeno (výchozí: 125). Limit zabraňuje vykazování některých legitimních, nekvalitních zarovnání, ale očekáváme, že se jedná o žádoucí kompromis pro většinu aplikací.,
Postupně Maq-jako vyhledávání
Motýlek umožňuje uživateli vybrat počet nesouladu povoleno (výchozí: dva) v high-end kvalitní čtení (výchozí: první 28 základy), stejně jako maximální přijatelnou kvalitu vzdálenosti z celkové zarovnání (výchozí: 70). Kvalitní hodnot se předpokládá, že podle definice v PHRED , kde p je pravděpodobnost chyby a Q = -10log p.
Jak číst a jeho zpětné doplnění jsou kandidáty pro zarovnání na vztažnou. Pro přehlednost se tato diskuse zabývá pouze orientací vpřed., Viz další datový soubor 1 (doplňková diskuse 2) pro vysvětlení toho, jak je začleněn zpětný doplněk.
prvních 28 bází na vysoce kvalitním konci čtení se nazývá „semeno“. Semeno se skládá ze dvou polovin: 14 bp na vysokou kvalitu (obvykle 5′ konec) a 14 bp na low-end kvalitní, tzv. hi-půl “ a „lo-půlka‘, resp., Za předpokladu, že výchozí politika (dvě neshody povoleno v semeni), oznamovanou zarovnání bude spadat do jedné ze čtyř případů: žádný nesoulad v semeno (případ 1); ne neshody v hi-půl, jednu nebo dvě neshody v lo-polovina (případ 2), žádný nesoulad v lo-půl, jednu nebo dvě neshody v hi-polovina (případ 3); a jeden nesoulad v hi-polovina, jedna neshoda v lo-polovina (případ 4).
všechny případy umožňují libovolný počet nesouladů v nonseed části čtení a všechny případy jsou také předmětem omezení vzdálenosti kvality.,
Motýlek algoritmus se skládá ze tří fází, které se střídají mezi pomocí dopředu a zrcadlo indexů, jak je znázorněno na Obrázku 3. Fáze 1 používá zrcadlový index a vyvolá zarovnání k nalezení zarovnání pro případy 1 a 2. Fáze 2 a 3 se spolupracovat na nalezení zarovnání pro případ 3: 2. Fáze najde částečné zarovnání s nesoulad pouze v hi-půl a fáze 3 pokusy rozšířit tyto částečné zarovnání do plné zarovnání. Nakonec fáze 3 vyvolá zarovnávač, aby našel zarovnání pro případ 4.,

tři fáze Motýlek algoritmus pro Maq-jako politika. Třífázový přístup najde zarovnání pro případy dvou neshod 1 až 4 při minimalizaci zpětného sledování. Fáze 1 používá zrcadlový index a vyvolá zarovnání k nalezení zarovnání pro případy 1 a 2. Fáze 2 a 3 se spolupracovat na nalezení zarovnání pro případ 3: 2. Fáze najde částečné zarovnání s nesoulad pouze v hi-půl, a fáze 3 pokusy rozšířit tyto částečné zarovnání do plné zarovnání., Nakonec fáze 3 vyvolá zarovnávač, aby našel zarovnání pro případ 4.
výsledky
hodnotili Jsme výkon Motýlek pomocí čte od 1000 Genomů projektu pilot (National Center for Biotechnology Information Krátké Čtení Archivu:SRR001115). Celkem 8,84 milionu čtení, asi jeden pruh dat z přístroje Illumina, bylo upraveno na 35 bp a zarovnáno s lidským referenčním genomem . Není-li uvedeno jinak, čtená data nejsou filtrována ani upravena (kromě ořezávání) z toho, jak se objevují v archivu., To vede k asi 70% až 75% čtení zarovnání někde genomu. Podle našich zkušeností je to typické pro surová data z archivu. Agresivnější filtrování vede k vyšším rychlostem zarovnání a rychlejšímu zarovnání.
všechny běhy byly provedeny na jednom CPU. Bowtie speedups byly vypočteny jako poměr časů zarovnání nástěnných hodin. Obě nástěnné hodiny a CPU časy jsou uvedeny prokázat, že vstupní / výstupní zatížení a CPU tvrzení nejsou významné faktory.
čas potřebný k sestavení indexu Bowtie nebyl zahrnut do doby běhu Bowtie., Na rozdíl od konkurenčních nástrojů, Bowtie může znovu použít předpočítaný index pro referenční genom v mnoha zarovnání běží. Předpokládáme, že většina uživatelů tyto indexy jednoduše stáhne z veřejného úložiště. Stránka Bowtie poskytuje indexy pro aktuální sestavení lidských, šimpanzů, myší, psů, potkanů a Arabidopsis thaliana genomů, stejně jako mnoho dalších.
Výsledky byly získány na dvou hardwarových platforem: stolní pracovní stanice s 2,4 GHz Intel Core 2 procesor a 2 GB RAM; a velké paměti serveru s čtyři-core 2,4 GHz, AMD Opteron procesor a 32 GB RAM., Označují se “ PC “ a „server“. Oba PC a server spustit Red Hat Enterprise Linux jako vydání 4.
srovnání SOAP a Maq
Maq je populární aligner, který patří mezi nejrychlejší konkurenční open source nástroje pro sladění milionů Illumina čte do lidského genomu. SOAP je další nástroj s otevřeným zdrojovým kódem, který byl hlášen a použit v projektech s krátkým čtením .
Tabulka 1 představuje výkon a citlivost Motýlek v0.9.6, SOAP v1.10, a Maq v0.6.6. Mýdlo nelze spustit na PC, protože stopa paměti SOAP přesahuje fyzickou paměť počítače. Mýdlo.,byla použita contigova verze binárního mýdla. Pro srovnání s MÝDLEM, Motýlek byl vyvolán s ‚-v 2‘ napodobovat MÝDLO je výchozí odpovídající politiky (který umožňuje až dvě neshody v zarovnání a ignoruje hodnoty kvality), a s ‚–maxns 5‘ simulovat MÝDLO je výchozí politika filtrování čte s pěti nebo více ne-důvěra základny. Pro Maq srovnání Motýlek je spustit s jeho default politiky, která napodobuje Maq je výchozí politika umožňuje až dvě neshody v prvních 28 základny a prosazování celkový limit ze 70 na součet hodnoty kvality na všech neodpovídající číst pozic., Aby byla paměťová stopa Bowtie více srovnatelná s MAQ, Bowtie je ve všech experimentech vyvolána volbou ‚-z‘, aby se zajistilo, že v paměti bude současně pouze index vpřed nebo zrcadlo.
počet čte souladu naznačuje, že MÝDLO (67.3%) a Motýlek -v 2 (67.4%) mají srovnatelnou citlivost. Z čte zarovnány buď MÝDLO nebo Motýlek, 99.7% byly zarovnány oba 0.2% byly zarovnány Motýlek, ale ne MÝDLO, a 0,1% byly zarovnány MÝDLO, ale není Motýlek. Maq (74,7%) a Bowtie (71,9%) mají také zhruba srovnatelnou citlivost, ačkoli Bowtie zaostává o 2,8%., Z čte zarovnány buď Maq nebo Motýlek, 96.0% byly zarovnány oba, 0.1% byly zarovnány Motýlek, ale ne Maq, a 3,9% byly zarovnány Maq ale není Motýlek. Z čtení mapovaných Maq, ale ne Bowtie, téměř všechny jsou způsobeny flexibilitou v algoritmu zarovnání Maq, který umožňuje některým zarovnáním mít tři nesoulady v osivu. Zbytek čte mapována Maq ale ne Motýlek jsou z důvodu Motýlek je ustupování stropu.
MAQ ‚s documentation zmiňuje, že čtení obsahující“ poly-a artefakty “ může narušit výkon Maq., Tabulka 2 Představuje výkon a citlivost Bowtie a Maq, když je sada čtení filtrována pomocí příkazu MAQ ‚catfilter‘ k odstranění artefaktů poly-a. Filtr eliminuje 438,145 z 8,839,010 čte. Další experimentální parametry jsou totožné s parametry experimentů v tabulce 1 a zde platí stejná pozorování relativní citlivosti Bowtie a Maq.
Délka čtení a výkon
jak se technologie sekvenování zlepšuje, délky čtení rostou za 30-bp na 50-bp, které se dnes běžně vyskytují ve veřejných databázích., Bowtie, Maq, a podpora soap čte délky až 1,024, 63, A 60 bp, příslušně, a Maq verze 0.7.0 a novější podporují délky čtení až 127 bp. Tabulka 3 ukazuje výsledky výkonu, když se tři nástroje používají k zarovnání tří sad 2 m untrimmed reads, sady 36 bp, sady 50 bp a sady 76 bp, s lidským genomem na platformě serveru. Každá sada 2 M je náhodně vybraných z většího souboru (NCBI Krátké Čtení Archivu: SRR003084 pro 36-bp, SRR003092 pro 50-bp, SRR003196 76-bp)., Čte byly odebrány vzorky tak, že tři sady 2 M mají jednotné per-základní míra chyb vypočtená z per-základní Phred kvality. Všechny čtení procházejí maqovým „catfilterem“.
Motýlek, je spustit, jak v jeho Maq-jako výchozí režim a v jeho MÝDLO-jako-v 2′ režimu. Bowtie je také dána možnost ‚- z‘, aby bylo zajištěno, že pouze index vpřed nebo zrcadlo je rezidentní v paměti najednou. Maq v0.7.1 byl použit místo Maq v0.6.6 pro 76-bp, protože v0.6.,6 nelze zarovnat čte déle než 63 bp. Mýdlo nebylo spuštěno na sadě 76-bp, protože nepodporuje čtení delší než 60 bp.
výsledky ukazují, že maqův algoritmus celkově měří lépe na delší délky čtení než Bowtie nebo mýdlo. Bowtie v mýdlovém režimu „- v 2 “ se však také velmi dobře váží. Bowtie ve svém výchozím režimu Maq-like váhy dobře od 36-bp do 50-bp čte, ale je podstatně pomalejší pro 76-bp čte, i když je stále více než řádově rychlejší než Maq.,
paralelní výkon
zarovnání lze paralelizovat distribucí čtení napříč souběžnými podprocesy vyhledávání. Bowtie umožňuje uživateli zadat požadovaný počet vláken (volba-p); Bowtie pak spustí zadaný počet vláken pomocí knihovny pthreads. Vlákna Bowtie se vzájemně synchronizují při načítání čtení, výstupu výsledků, přepínání mezi indexy a provádění různých forem globálního účetnictví, jako je označení čtení jako „hotovo“., V opačném případě mohou vlákna pracovat paralelně a podstatně urychlit zarovnání na počítačích s více jádry procesoru. Paměťový obraz indexu je sdílen všemi vlákny, a tak se stopa při použití více vláken podstatně nezvyšuje. Tabulka 4 ukazuje výsledky pro běh Motýlek v0.9.6 na čtyřech-core server s jedním, dvěma a čtyřmi závity.,
Index budovy
Motýlek využívá flexibilní indexování algoritmus, který může být nakonfigurován tak, aby kompromis mezi využitím paměti a čas běží. Tabulka 5 ilustruje tento kompromis při indexování celého lidského referenčního genomu (NCBI build 36.3, contigs). Běhy byly prováděny na platformě serveru. Indexer byl spuštěn čtyřikrát s různými horními limity využití paměti.,
nahlášené časy porovnat příznivě s zarovnání časů konkurenčních nástrojů, které provádět indexování během zarovnání. Méně než 5 hodin je nutné pro Motýlka jak budovat a dotaz celek-lidské index s 8.84 milionů čte od 1000 Genome project (NCBI Krátké Čtení Archivu:SRR001115) na serveru, více než šestinásobně rychleji než ekvivalentní Maq spustit., Spodní řádek ukazuje, že Motýlek indexer, s vhodnými argumenty, je paměť dostatečně efektivní pro provoz na typické pracovní stanice s 2 GB RAM. Další datový soubor 1 (doplňkové diskuse 3 a 4) vysvětluje algoritmus a obsah výsledného indexu.
Software
Bowtie je napsán v C++ a používá SeqAn knihovnu . Převodník do formátu mapování Maq Používá kód z Maq.